私たちが作成する サービスの 各アプリケーションコンポーネントは、適切に実行および機能するためにいくつかのリソースを必要とします。 必要なリソースの量を正確に予測することは、影響を与える可能性のある可動部分が多く存在するので、ほとんど不可能です。 必要なメモリ、CPU、またはネットワーク帯域幅の量は、作業量が変化するにつれて、アプリケーションのライフサイクルを使用して変化する可能性があります。 ほぼすべてのアプリケーションには、常に満たす必要があるパフォーマンス要件があります。 ワークロードが変化するに応じて、必要なパフォーマンス レベルを維持できる必要があります。 これが、Azure の自動スケールが機能する場所であり、メカニズムであるため、これを実現するために使用できます。
自動スケール
下の図 1 では、アプリケーションの負荷とリソースの合計制限があります。 自動スケーリングが設定されていない場合、 ユーザー 接続されているユーザーと ウェブ アプリケーションに接続しようとしているユーザーは、パフォーマンスに直面する可能性があります 問題 使用可能なリソースの制限により、 図 1.2 トラフィックに対処できません。 ただし、図 2 を見ると、トラフィックとアプリケーションの負荷によって、利用可能なリソースが同時に増加することがわかります。 これは自動スケールの利点です。
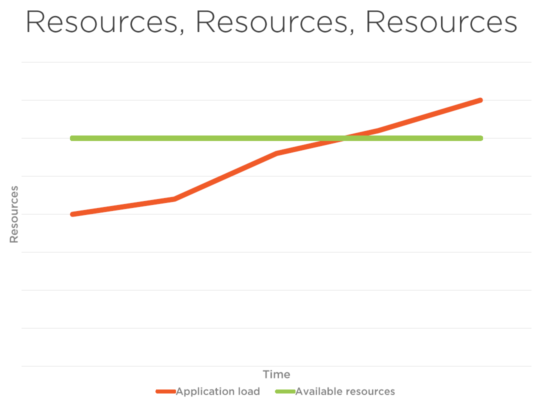
図 1
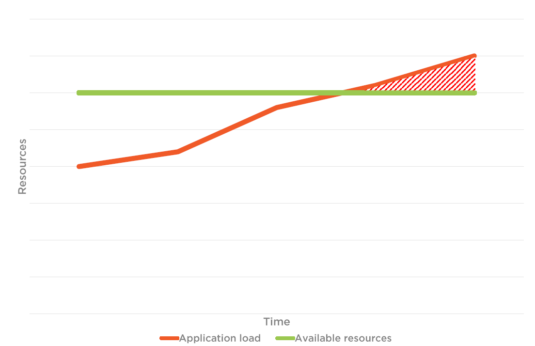
図 1.2
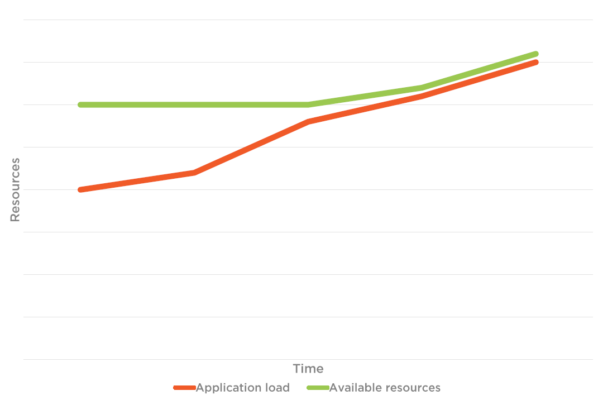
図 2
Azure でソリューションを計算する
- アプリ サービス. Azure アプリ サービスは、Web アプリ、モバイル バックエンド、RESTful API を構築するための完全に管理された Web ホスティング サービスです。 小規模な Web サイトからグローバルに拡張された Web アプリケーションまで、Azure には価格とパフォーマンスのオプションがあり、ニーズに合わせて設定できます。
- Azure クラウド サービス Azure クラウド サービスは、サービスとしてのプラットフォーム (PaaS) の例です。 Azure App Service と同様に、このテクノロジは、スケーラブルで信頼性が高く、運用コストが低いアプリケーションをサポートするように設計されています。 Azure クラウド サービスを使用する VM に独自のソフトウェアをインストールし、リモートからアクセスできます。
- Azure サービス ファブリック. Azure Service Fabric は、スケーラブルで信頼性の高いマイクロサービスとコンテナーのパッケージ化、デプロイ、管理を容易にする分散システム プラットフォームです。 Service Fabric は、コンテナーで実行されるエンタープライズ クラス、階層 1、およびクラウド スケールのアプリケーションを構築および管理するための次世代プラットフォームです。
- Azure の機能: Azure Functions を使用すると、開発者はデータ ソースやメッセージング ソリューションに接続して行動できるため、イベントの処理と対応が容易になります。 開発者は Azure Functions を活用して、さまざまなアプリケーション、モバイルデバイス、IoT デバイスからアクセスできる HTTP ベースの API エンドポイントを構築できます。
- 仮想マシン: Azure 仮想マシンを使用すると、クラウド内の仮想マシンをサービスとしてのインフラストラクチャとして作成して使用できます。 Azure またはパートナーから提供されるイメージを使用することも、独自の仮想マシンを作成することもできます。
自動スケールの種類
垂直自動スケール
垂直スケーリングとは、VM のサイズを変更することです。 より多くのハードウェア リソースを持つより大きな VM が必要な場合はスケールアップし、一方で、利用可能なすべてのリソースが必要ではなく、VM のサイズを小さくする場合に備えてスケールダウンします。 この VM でホストされているアプリケーションは、どちらの場合も変更されません。 このタイプのスケーリングは、リソース消費が最適化されていないため、特にクラウド環境では あまり効率的ではありません。 もう 1 つの欠点は、サイズを変更するために仮想マシンを停止する必要がある点です。 これは、VM の停止、サイズ変更、および再起動中にオフラインになる必要があり、これらのアクションは通常時間がかかるため、アプリケーションに影響します。 もちろん、VM は変更せずに、新しい仮想マシンを必要なサイズでプロビジョニングし、新しい VM の準備が整ったらアプリケーションを移動できます。 この場合も、移動中はアプリケーションをオフラインにする必要がありますが、アプリを移動するプロセスは はるかに短くなります。
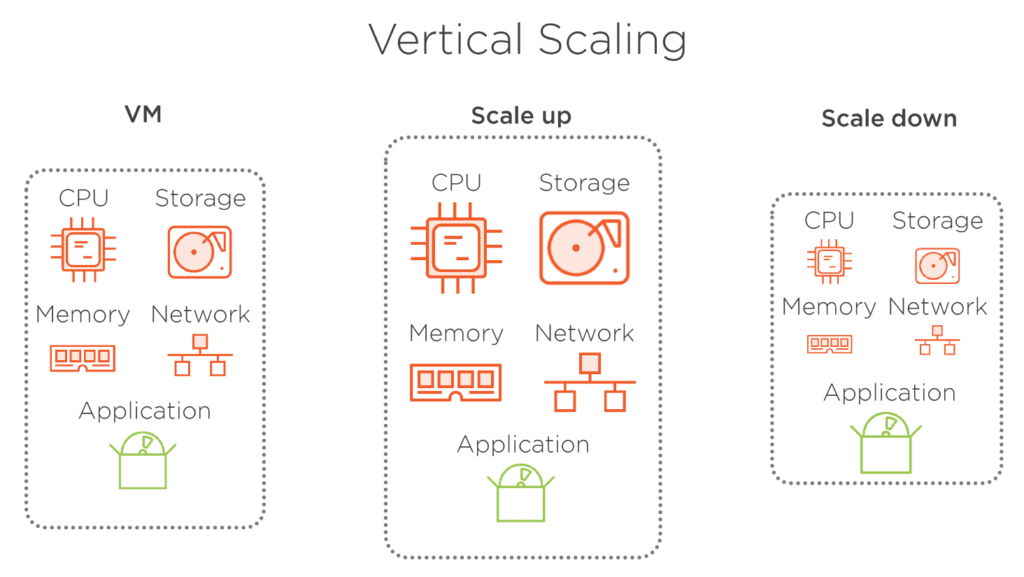
図 3
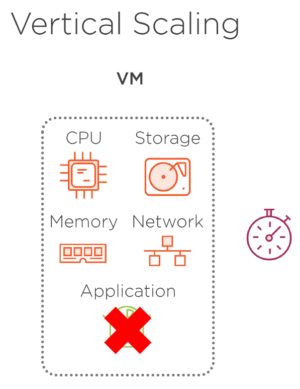
図 3.1 – 垂直方向のスケーリングが行われるとき、再起動に時間がかかるため、アプリケーションが使用できなくなります。
水平自動スケール
水平スケーリングとは、同じ VM の複数のインスタンスに負荷を分割することで、実行中の VM の数を変更し、必要なパフォーマンスを維持することを意味します。 仮想マシンのサイズは変わりません。 スケール アウトによって数を増やすだけ、またはスケールインすることで一度に実行中の VM の数を減らします。 この方法を使用することで、小さな VM サイズから開始し、リソースの消費をできるだけ最適に保つことができます。 また、アプリケーションのインスタンスは常に少なくとも 1 つ実行するので、ダウンタイムはありません。 水平スケーリングでは、実行中の VM 間で負荷を均等に分散するためにロード バランサーが必要です。 しかし、幸いなことに、Azure は、この操作を実行し、その操作を実行する必要はありません。
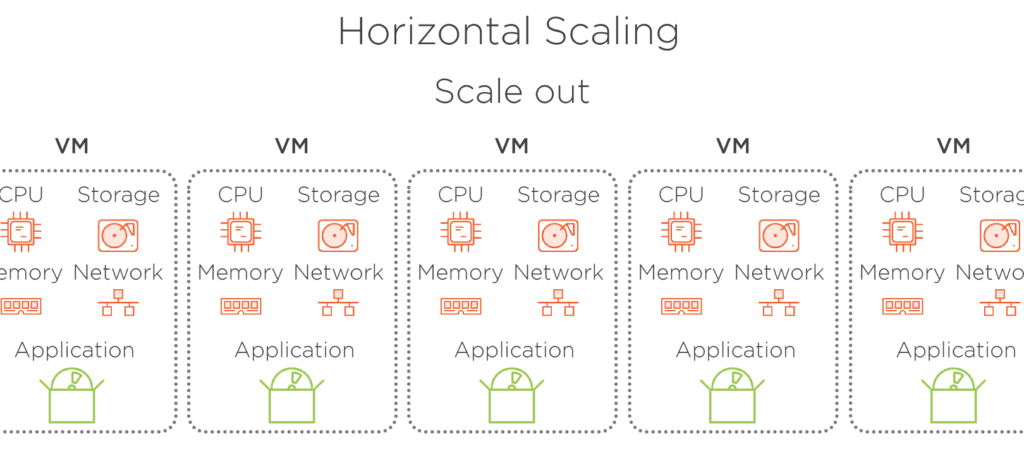
図 5. トラフィックが増加したときにスケールアウト。
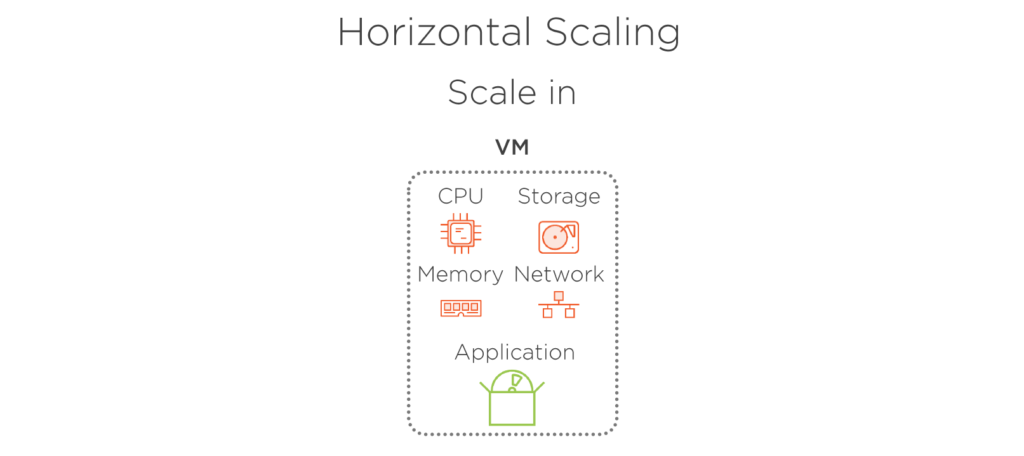
図 5.1 – トラフィックが減少したときにスケールアウト
監視とアラート
Azure で追加のリソースがサービスに追加されているかどうかを監視する方法は多数ありますが、その一部は非常に複雑です (たとえば、サービスの [スケーリング] ブレード (この場合は図 6)。 これは管理者が好む方法ですが、所有者と貢献者は推奨されません。 ユーザーが表示できるようにするには、Azure ポータルにログインする必要があります。
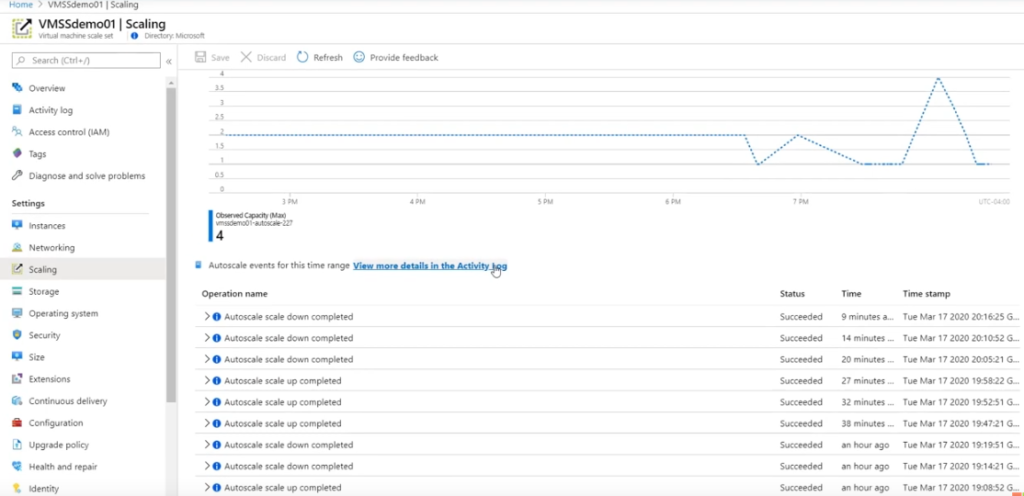
図 6
アラート
自動スケール アウトとスケール イン (App service) が発生したときにユーザーに通知するように選択できます。
図 7
既定では、アプリケーションの分析情報は、サーバーの応答時間や要求などに関する洞察を提供するアプリ サービスに使用されます。
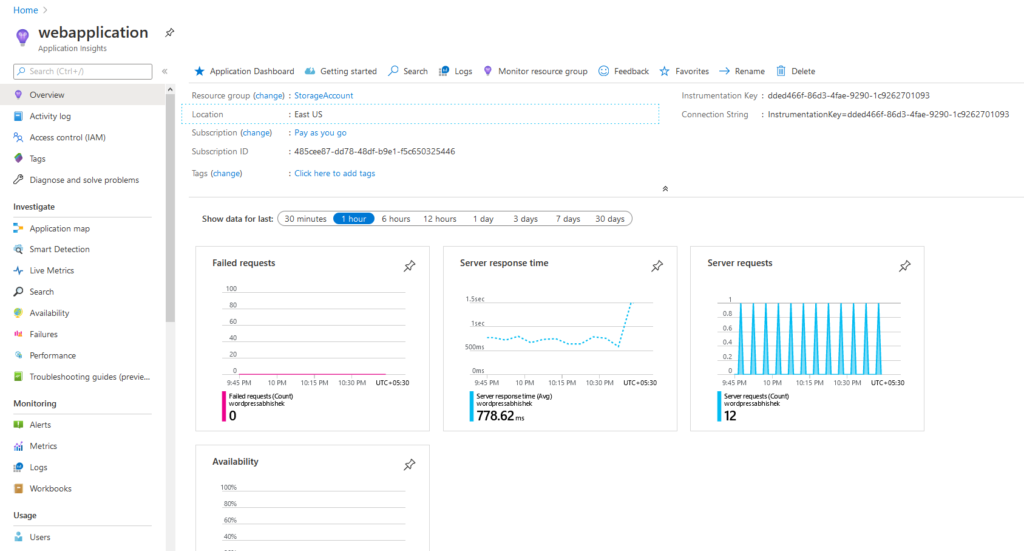
図 8. アプリ サービスが受信した要求に対する平均サーバー応答時間を示すアプリケーションインサイト。
これは、アプリ サービスで自動スケールを構成する方法です。 まず、スケールアウトの構成 > > スケールの追加条件 > CPU、RAM、要求などの適切なメトリックを選択します。 > 保存し、それが完了しました。
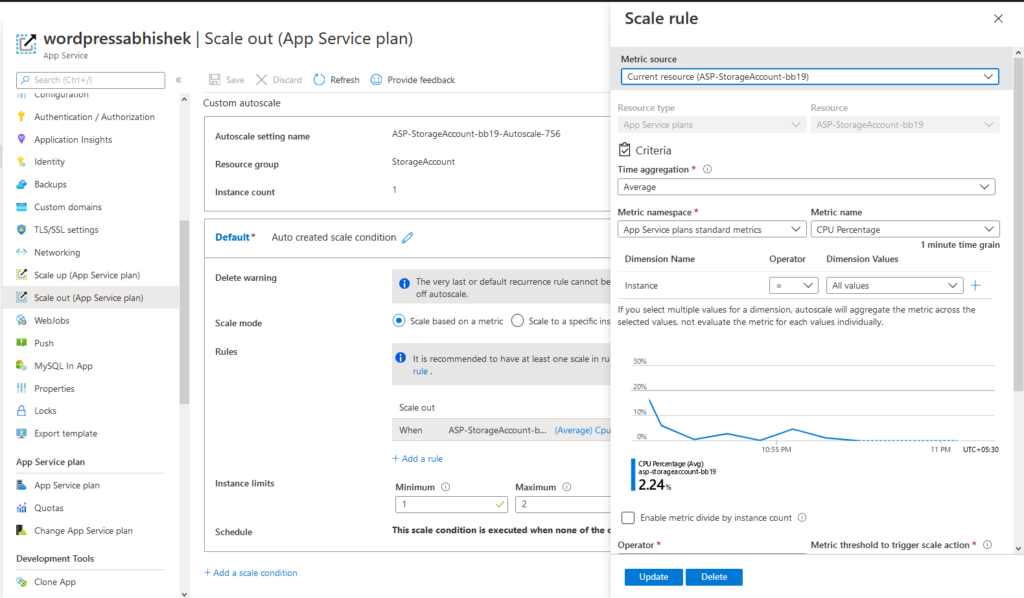
図 9. アプリ サービス プランでの自動スケール条件の構成
Azure 自動スケーリングを使用する場合、ロード バランサーや トラフィック マネージャーなどの実装方法について心配する必要はありません。 Azure がすべてを管理します。
注: スタンドアロン VM には追加の構成が必要です。 ただし、仮想マシン スケール セットでは、自動スケール時に管理操作は必要ありません。 ロード バランサーは自動的に作成されます。
Azure アプリ サービスには、Azure によって処理されるブラインド自動スケール方法があり、リソース内で個別に使用されるサービスは表示されません。 代わりに、管理オーバーヘッドを削除します。 自動スケールが達成されるという点を念頭に置いて、パフォーマンスの問題をほとんどまたはまったく感じられません。 Azure では、ほとんどの自動スケールの条件を指定する以外に、ほとんどの自動スケール 部分を処理しますが、ユーザーが行う必要があまりありません。 すべてがスムーズに処理されます。
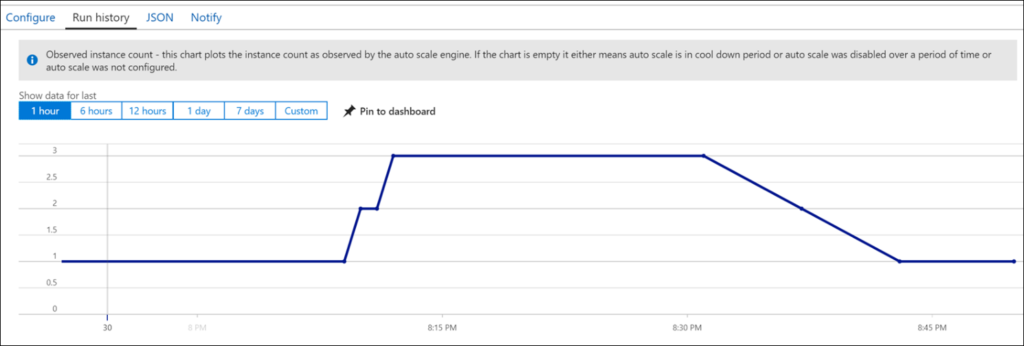
図 10 には、言及した条件が満たされると自動的にスケールする VMSS (仮想マシン スケール セット) があります。
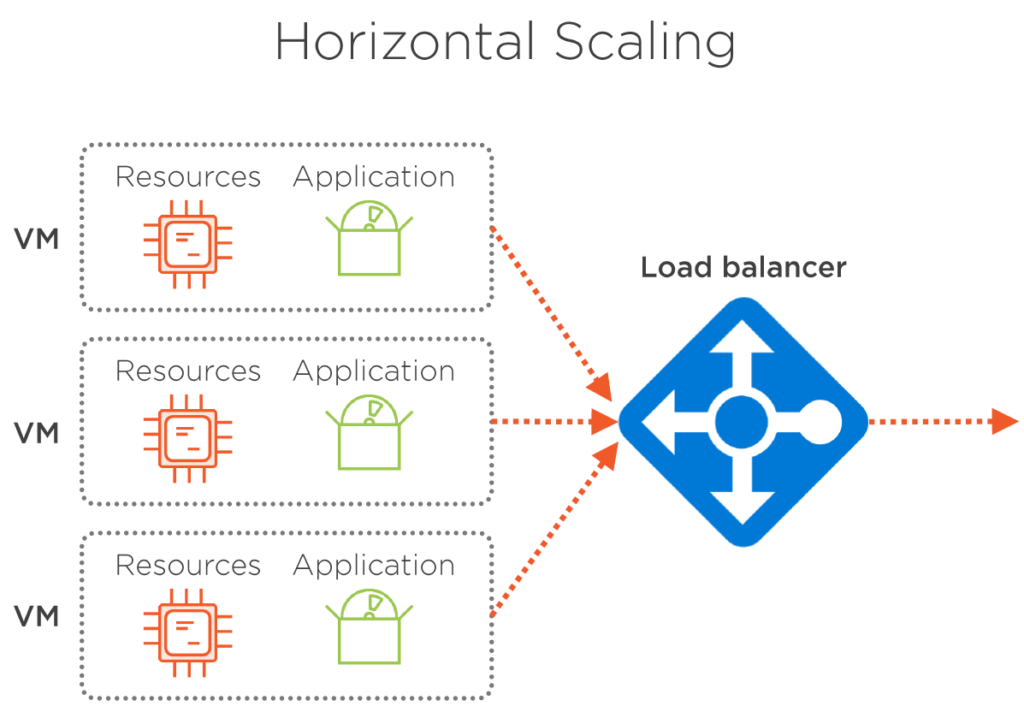
図10。 ロード バランサーを使用した仮想マシン スケール セット。
Azure 自動スケールのテスト
テストは、Web アプリケーションの不可欠な部分です。 テストなしでは、 ウェブ サーバーがトラフィックを処理できるかどうかを確実に知ることはできません。 ストレス テスト、 負荷テストは、テストの数少ない例です。 純粋に Azure で処理するには、Azure portal 内で DevOps 組織にサインアップし、プロジェクトを作成すると、次の ページにリダイレクトされます。

図 11. テスト用の DevOps ダッシュボード
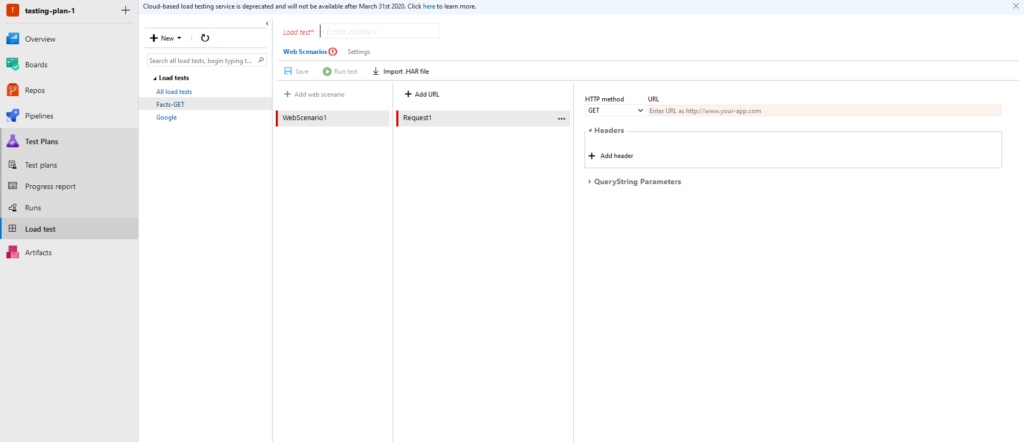
図 12. テスト目的で URL を追加し、テストに使用されているサービスのメトリックを確認できます。
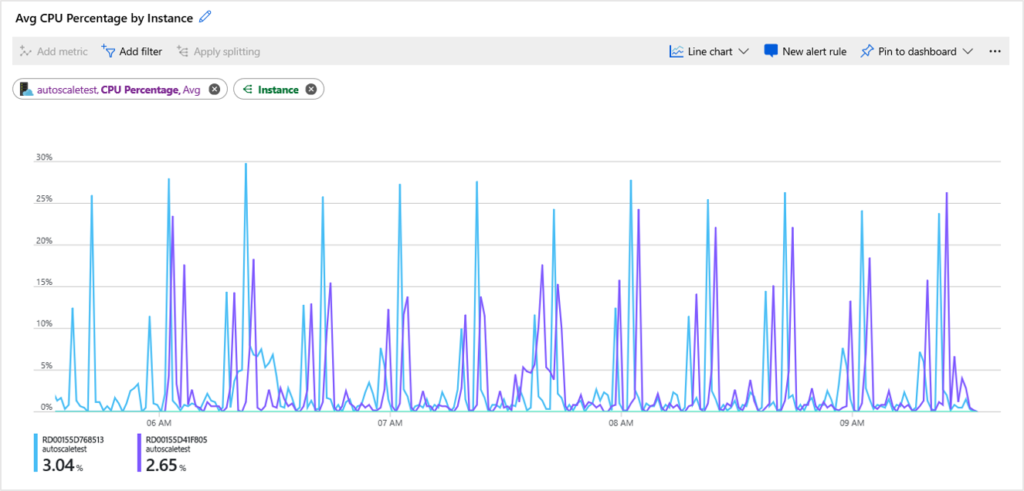
図 13. VM 上にあるテスト済みアプリケーションの CPU グラフ。
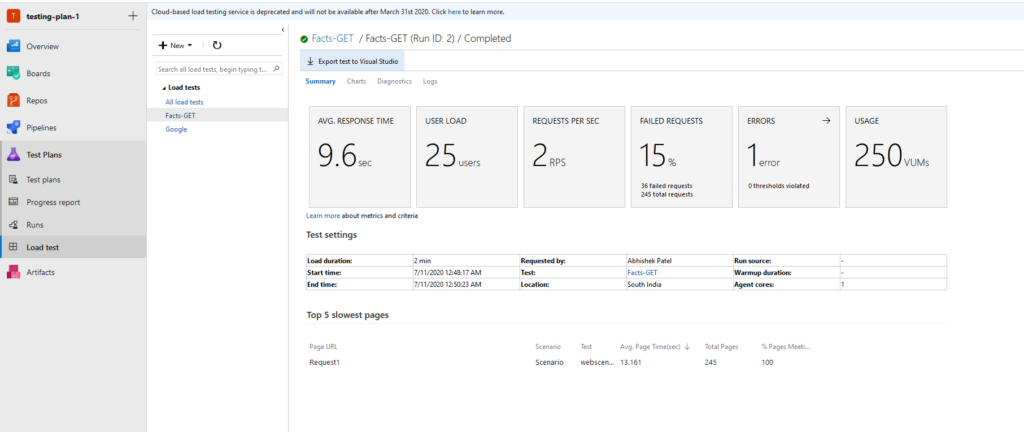
図 14. 応答時間、ユーザー負荷、秒あたりの要求数 などの詳細を含む GET API のサンプル結果。
LoadView を使用して Azure の自動スケールが正しく機能することを確認する
今では分かるように、CPU、RAM、IOの量に達すると、自動スケールが発生します。 図 15 では、このグラフは、特定の URL またはエンドポイントに対してテストを実行するときに LoadView によって提供されるレポートに含まれています。 最初のグラフは、ロード テスト戦略に従ってサイトを訪れるユーザーの数が一定であり、以降の時点では、平均応答時間が大幅に増加します。
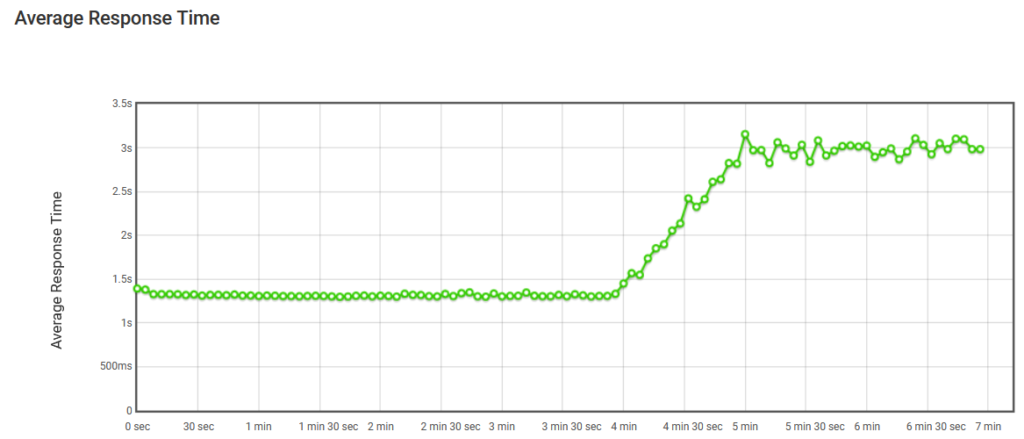
図 15. 自動スケールなしの平均応答時間
ただし、自動スケールには利点があります。 図 16 では、ユーザーが増加すると、Web アプリケーションをホストするインスタンスは条件に従ってスケール アウトされるため、自動スケールが完了しても平均応答時間は影響を受けません。 ユーザーが接続されなくなると、予期しない負荷を処理するために作成されたインスタンスは終了し、最初のカウントだけがそのまま残ります。
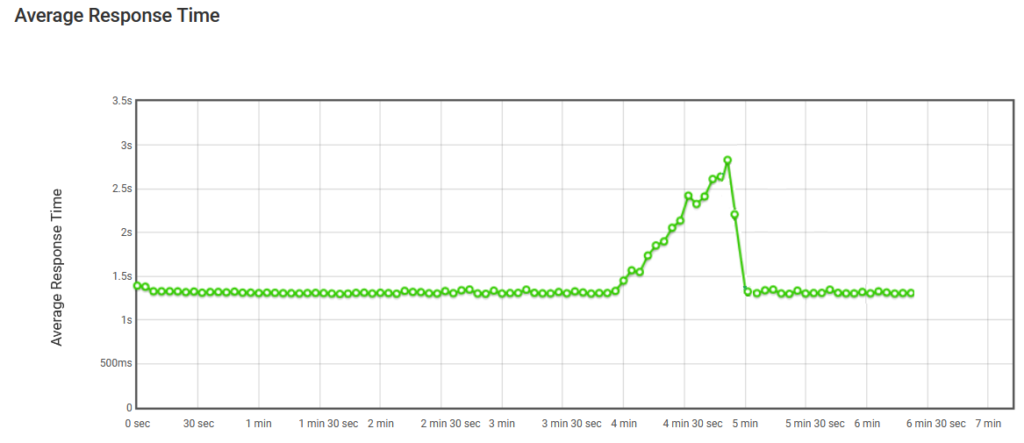
図 16. 自動スケールによる平均応答時間
図 17 では、 LoadView によって提供されるロード テストは、セッションが増加し続けるときにセッションを使用してアプリをテストする方法を提供し、適切なテストとアプリの自動スケーリングに役立ちます。
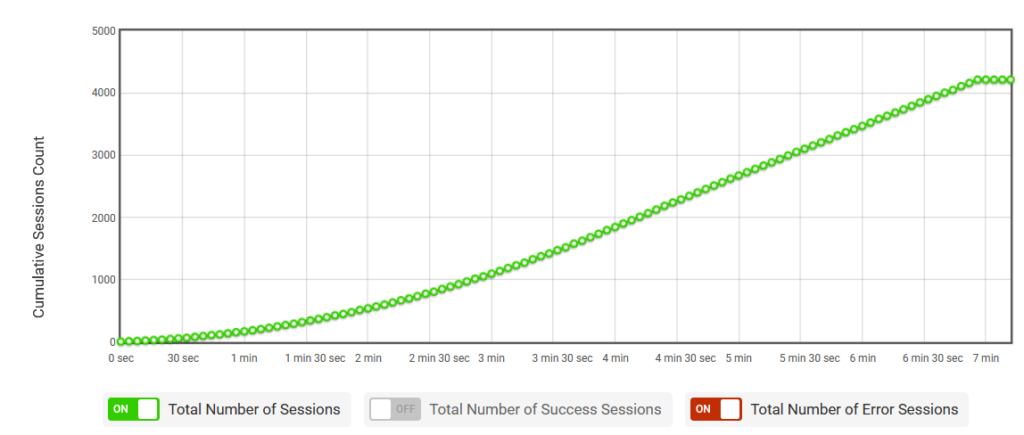
図 17. 累積セッション数
Azure 自動スケールのテスト: 結論
Microsoft Azure の自動スケールを実装する場合、ロード バランサー、トラフィック マネージャーなどを実装する方法について心配する必要はありません。 Azure では、すべてを管理し、テストするアプリケーションの負荷を処理するために、適切な量のリソースが実行されていることを確認します。 ただし、LoadView のようなソリューションを使用すると、自動スケールが正しく実行され、リソースが追加された場合にパフォーマンスが低下することがなくなります。