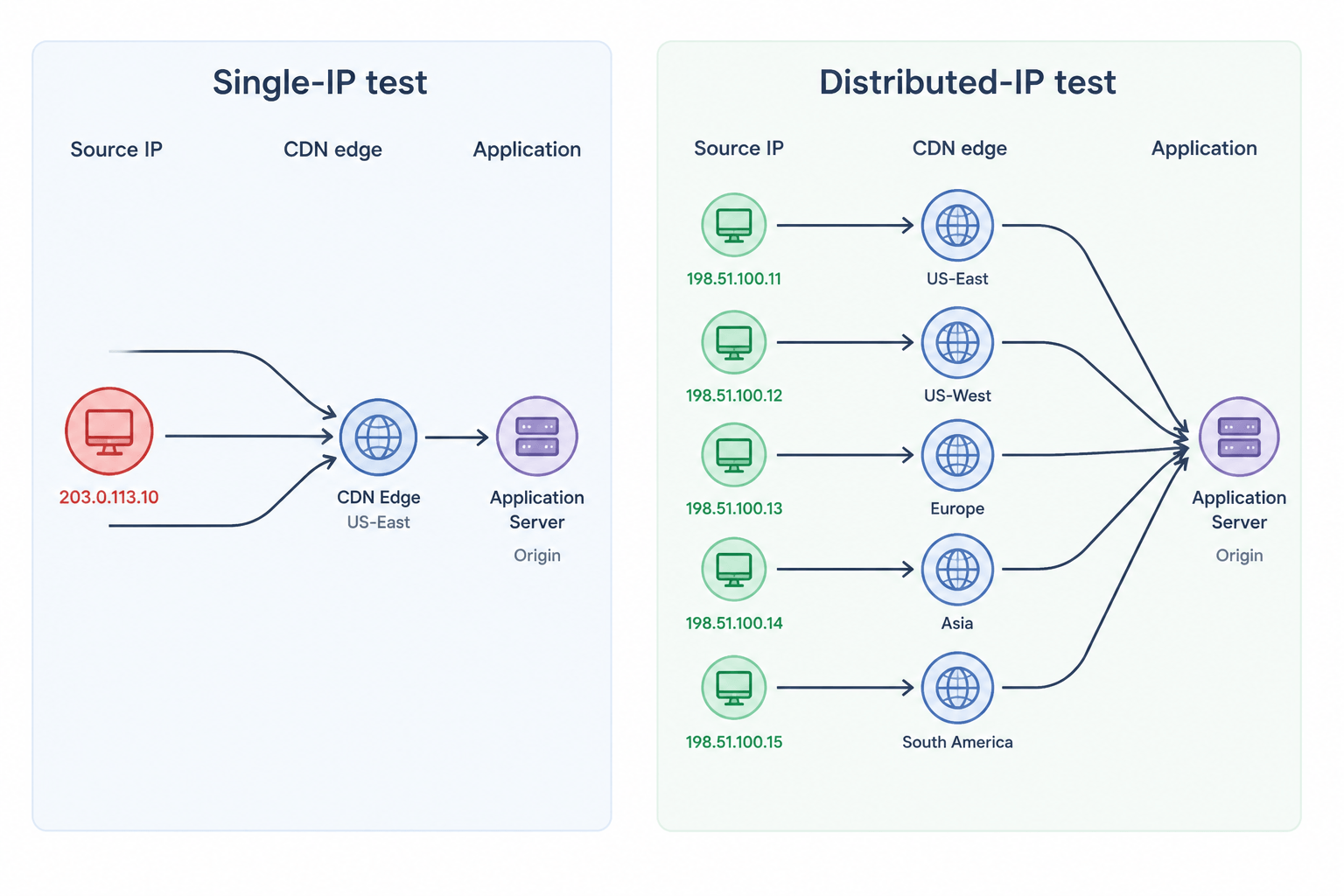
- Por qué una prueba con una sola IP parece correcta pero no lo es
- Siete modos específicos de fallo
- La trampa del egreso en la nube
- Cómo es una distribución realista de IPs
- IP única vs IP distribuida: cuándo usar cada una
- Escenarios del mundo real
- Cómo LoadView maneja las pruebas de carga multi-IP
- Lista de verificación para la implementación
- Preguntas frecuentes
Por qué una prueba con una sola IP parece correcta pero no lo es
Una prueba de carga con una sola IP puede parecer exitosa en papel. El script se ejecuta, los paneles se llenan y la latencia se mantiene dentro del rango objetivo. El problema es que los resultados a menudo reflejan más la configuración de la prueba que el tráfico real de producción.
El tráfico de producción no llega desde una sola dirección. Un endpoint orientado al consumidor ve tráfico de miles de ISP residenciales, operadores móviles, NAT corporativos y proxies de centros de datos. Cada solicitud llega a un nodo CDN diferente, atraviesa un middlebox distinto y accede a un fragmento diferente de la piscina de conexiones. Cuando se reduce toda esa diversidad a una única IP de origen, cada capa que utiliza la dirección de origen…el vestido comienza a comportarse de maneras que no tienen contraparte en el mundo real.
El resultado es un dato de rendimiento engañoso que no refleja el comportamiento real en producción.
Siete Modos Específicos de Falla de Pruebas de Carga con IP Única
Las pruebas de carga con IP única pueden distorsionar o pasar por alto varios comportamientos del mundo real.
1. Los Limitadores de Tasa Devuelven el Número Incorrecto
Los limitadores de tasa modernos operan por identificador de origen, y el identificador más común es la IP de origen. Los algoritmos de token-bucket, ventana fija y ventana deslizante comparten esa propiedad. Incluso los equipos que también establecen límites basados en tokens de autenticación o IDs de usuario casi siempre aplican límites por IP subyacentes; la capa IP es la que protege la aplicación del abuso no autenticado. Cuando una carga pesada de usuarios virtuales genera todo su tráfico desde una IP, el limitador ve esa carga como un solo cliente y comienza a rechazar solicitudes mucho antes de que la aplicación sienta estrés. La aplicación parece rápida porque el limitador absorbió la carga. En producción, la misma tasa total de solicitudes llegaría desde miles de IPs de origen distintas y el limitador dejaría pasar la carga.
La imagen inversa también es cierta. Si el limitador tiene un presupuesto por IP generoso, una prueba con IP única nunca se acerca al límite agregado en el balanceador de carga. La aplicación recibe una paliza y el limitador nunca se activa, ocultando el hecho que el tráfico en producción sería parcialmente descartado.
2. WAFs y la Detección de Bots se Activan en el Arnés
Un WAF que monitorea patrones de solicitudes uniformes y abruptas desde una IP está haciendo exactamente el trabajo para el que fue diseñado. Ve la prueba de carga, identifica el tráfico y o bien regula la tasa, desafía o bloquea. Algunos equipos descubren esto solo cuando la prueba se estanca en un número de throughput sospechosamente redondo que resulta ser el umbral del WAF. Las pruebas que ejercitan rutas de protección DDoS necesitan fuentes diversas por la misma razón: estas defensas suelen ser independientes del WAF y dependen aún más de la diversidad de IPs de origen para activarse de forma realista.
Deshabilitar el WAF para la prueba “arregla” el síntoma y crea un problema peor: la ruta de prueba ya no coincide con la ruta en producción. El tráfico desde muchas IPs es la única manera de validar que la aplicación funcione mientras el WAF está activo a los umbrales de producción.
3. La Selección del Nodo del Borde del CDN se Colapsa a un Nodo
Los CDN enrutan las solicitudes al borde más cercano al cliente. Desde una IP, el tráfico llega a un solo nodo POP del borde. La caché se llena allí, todas las solicitudes posteriores acceden a almacenamiento caliente, y la prueba reporta latencia de acierto en caché durante toda la ejecución. Mientras tanto, la larga cola de bordes fríos en otras regiones nunca se ejercita. Cualquiera que lea guía sobre pruebas de carga en sitios web que usan redes de entrega de contenido (CDNs) sees esto llamado: el comportamiento de la caché es una función de la distribución de origen, no solo de la tasa de solicitudes.
El caso opuesto también importa. El comportamiento de protección del origen en fallos de caché, donde un CDN coagula fallos concurrentes en una sola recuperación del origen, es invisible desde una IP. No puedes validar la protección del origen sin tráfico que el CDN trate como independiente.
4. Las decisiones de enrutamiento Anycast y GeoDNS nunca se activan
Las IPs Anycast enrutan paquetes al centro de datos topológicamente más cercano. GeoDNS resuelve un nombre de host a diferentes IPs según la ubicación del resolvedor. Ambas decisiones ocurren antes de que la solicitud llegue a tu aplicación. Desde una única fuente de prueba, solo ves el centro de datos en el que aterriza tu ejecutor de prueba. El enrutamiento entre regiones, las rutas de conmutación por error y la latencia hacia regiones distantes permanecen sin probar.
Esto puede ser un punto ciego costoso. La prueba en una sola región pasa, la aplicación se despliega globalmente, y los usuarios en regiones que la prueba nunca tocó experimentan una latencia que los paneles nunca mostraron. Las pruebas de carga geodistribuidas existen precisamente para cerrar esta brecha.
5. La reutilización de grupos de conexión y la coalescencia HTTP/2 distorsionan el rendimiento
Los clientes HTTP/2 y HTTP/3 abren una conexión por origen y multiplexan solicitudes sobre ella. Desde una única IP con un solo cliente, la aplicación ve una conexión de larga duración que transporta miles de flujos. La contabilidad por conexión del servidor, las ventanas de control de flujo y el comportamiento de bloqueo en el frente de línea reflejan esa única conexión. En producción, tienes miles de conexiones, cada una con su propia ventana de control de flujo, cada una contribuyendo independientemente a la presión del programador.
El mismo efecto aparece en el balanceador de carga. Las métricas por conexión, la eliminación por tiempo de inactividad y el comportamiento de vaciado de reinicio suave se comportan de manera diferente bajo una conexión gruesa frente a miles de delgadas. Solo ves la distribución del número de conexiones en producción cuando generas carga desde muchos clientes distintos a través de muchas IPs; una prueba que no genera esa distribución no puede validar ninguno de estos aspectos.
6. Agotamiento de puertos efímeros y source-NAT en el generador
El rango de puertos efímeros de Linux da a una sola IP fuente solo decenas de miles de puertos por tupla de destino. Un generador de carga que empuja altas tasas de conexión desde una IP agota los puertos en segundos, y la prueba se estanca en el arnés en lugar del sistema bajo prueba. Los entornos en la nube empeoran esto: una instancia EC2 detrás de una puerta de enlace NAT comparte un grupo aún más pequeño con todo lo que sale por esa misma puerta. Los practicantes que han experimentado esto lo conocen como “el muro de que la prueba no avanzará más”, y está documentado en extensos informes sobre el agotamiento de puertos TCP en pruebas de IP única.
La solución no es solo generadores más potentes. Es más generadores de carga con sus propias IP de salida, por lo que la piscina de puertos se replica en lugar de compartirse.
7. La Observabilidad se Colapsa en un Solo Grupo
Muchos paneles de producción agrupan el tráfico por IP de origen, ASN o región geográfica. Una prueba de una sola IP crea un solo grupo, y cada alerta, percentil y métrica de saturación se colapsa en ese grupo. Los ingenieros que revisan la prueba no pueden saber si la latencia que ven es uniforme en todas las regiones o está concentrada en una sola. Tampoco pueden reproducir el corte que usan en un incidente real, donde el primer instinto es “muéstrame el p99 por región” o “muéstrame la tasa de error por ASN”. Tratar los parámetros de prueba de carga de la misma manera que los parámetros de producción requiere diversidad de origen en la entrada.
La Trampa del Egreso en la Nube
La mayoría de los equipos que intentan distribuir la prueba de carga a través de múltiples máquinas ejecutan esas máquinas en una cuenta de nube, en una región, detrás de un gateway NAT. El resultado es técnicamente multi-IP y prácticamente de fuente única. Cada paquete sale con una IP de origen del mismo ASN conocido del proveedor de la nube. Los WAFs, proveedores de detección de bots y proveedores edge mantienen datos de reputación sobre los rangos de egreso en la nube; muchos tratan el tráfico de esos rangos con un escrutinio extra por defecto.
Esto importa en dos direcciones. Primero, la aplicación ve la prueba como tráfico de centro de datos, que se enruta de manera diferente al tráfico residencial en cada CDN y en muchas implementaciones anycast. Segundo, tus pruebas se ejecutan desde el mismo vecindario de red que cargas de trabajo competidoras, lo que hace que la latencia base sea ruidosa y la reproducibilidad peor. Configuraciones genéricas de pruebas de carga AWS pueden abordar la escala pero no la diversidad de origen.
El realismo requiere que la red de inyección de carga abarque más de una nube, múltiples regiones y idealmente una mezcla de egreso de calidad de centro de datos y residencial (por ejemplo, combinar dos proveedores de nube con una red de salida residencial o de operador móvil) para que la mezcla de IP/geo que tu aplicación vea durante la prueba se parezca a la que ve en producción.
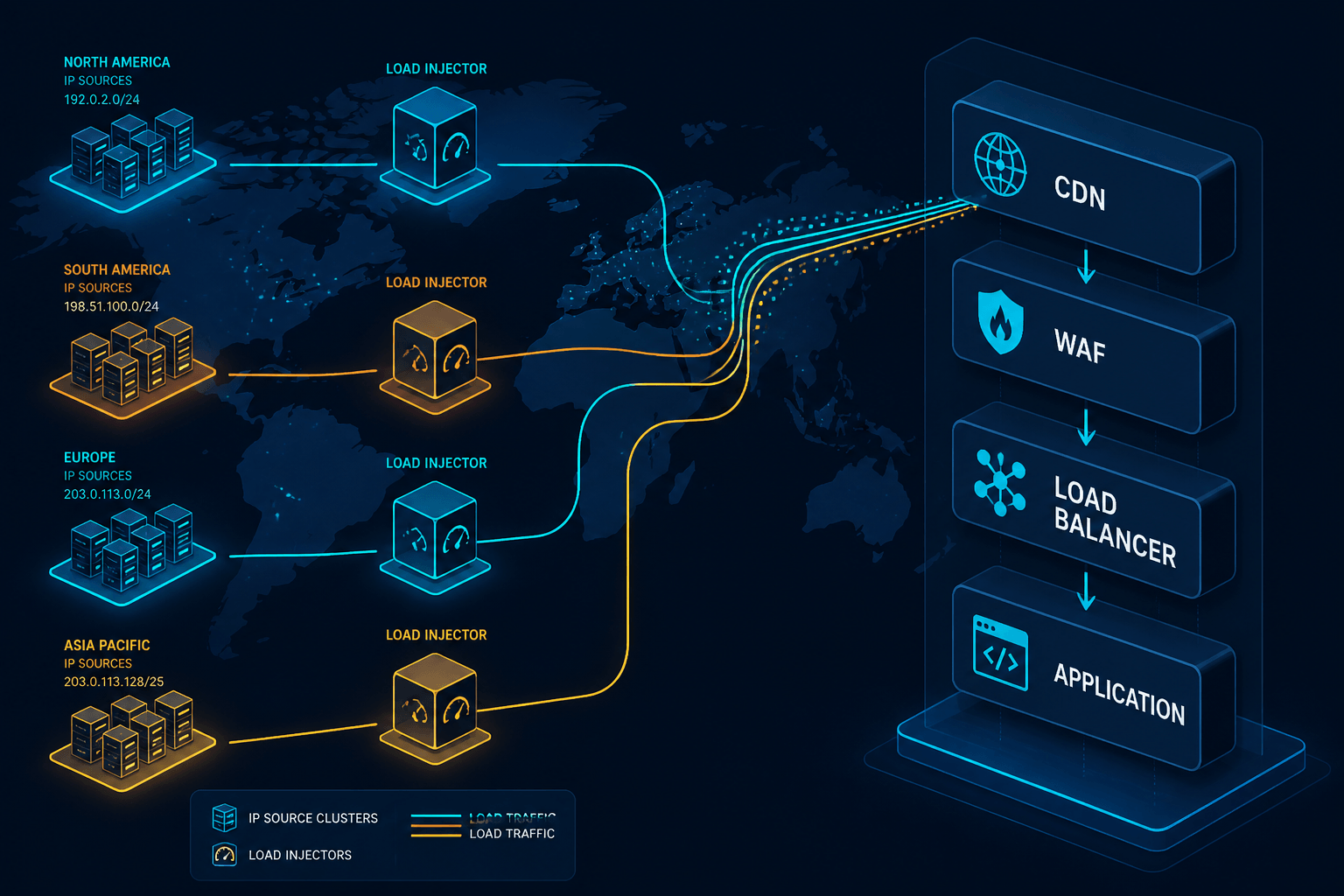
Cómo es Realmente una Distribución Realista de IP
“Muchas IP” no es un objetivo. El objetivo es una distribución que coincida con la producción. Tres propiedades importan.
Distribución geográfica. Si el 30 por ciento de los usuarios están en EMEA, el 30 por ciento en APAC y el 40 por ciento en las Américas, la prueba debe inyectar en aproximadamente esas proporciones. Esto es lo que impulsa el enrutamiento anycast realista y la selección del edge de la CDN. También revela las colas lentas que las pruebas en una sola región ocultan.
Diversidad de red. Mezclar ISPs residenciales, operadores móviles y redes de centros de datos expone la aplicación a toda la gama de comportamientos de MTU, pérdida de paquetes y middleboxes que se ven en producción. Una prueba que se ejecuta completamente en redes de centros de datos no detecta cómo las redes móviles renegocian TLS o cómo NAT de grado operador agrupa conexiones.
Volumen por IP que se asemeja a un usuario real. Una IP realista no genera mil solicitudes por segundo. Genera la tasa de solicitudes de algunos usuarios reales detrás de un NAT, más de vez en cuando un lote de un usuario avanzado. La simulación de usuario virtual que respeta el volumen por IP mantiene el límite de tasa y las interacciones con WAF del lado correcto de lo realista.
IP única vs IP distribuida: cuándo corresponde cada una
| Propósito de la prueba | ¿IP única aceptable? | Por qué |
|---|---|---|
| Microbenchmark de componente de un servicio backend | Sí | No hay ruta a internet, ni límites por IP, ni CDN. El componente es el sistema bajo prueba. |
| Prueba de humo de un despliegue | Sí | Estás verificando la corrección, no el rendimiento. |
| Validación de capacidad de un endpoint accesible por internet | No (en casi todos los casos) | Limitador de tasa, WAF, CDN y anycast distorsionan el resultado. |
| Prueba de escalabilidad pre-lanzamiento | No | Efectos de pool de conexiones, agotamiento de puertos y selección de edge rompen el modelo. |
| Validación de umbrales de límite de tasa por IP | No | Por definición, esto requiere muchas IPs fuente para probar el umbral. |
| Ajuste del health-check de balanceador de carga | A veces | Solo LB interno. LB público requiere fuentes diversas. |
| Validación de geo-enrutamiento y conmutación por error | No | Las decisiones solo se activan cuando el resolvedor y la IP fuente varían. |
Escenarios del mundo real
Escenario 1: un Checkout de Ecommerce que “pasa” hasta Black Friday
Considera un patrón común. Un minorista de ropa realiza una prueba de carga con muchos usuarios virtuales desde una sola región en la nube. La latencia p95 del checkout regresa cómodamente dentro del SLO. En Black Friday, el p95 salta a rangos de varios segundos y aumenta el abandono del carrito.
Dos cosas tienden a salir a la luz en este tipo de análisis post-incidente. La CDN sirvió la mayoría del tráfico de prueba desde un solo POPque se mantuvo caliente durante toda la ejecución. En producción, el tráfico se distribuyó en muchos POP, varios de los cuales se iniciaron en frío durante el pico. El segundo problema suele ser el límite de tasa por IP en un servicio descendente. La prueba alcanzó el techo para una IP al instante y se mantuvo por debajo de él durante toda la ejecución, lo que enmascaró una ruta de crecimiento ilimitado en la caché subyacente. La cobertura de HTTP concurrente versus navegadores concurrentes explica por qué la forma del arnés importa tanto como el recuento de usuarios.
Escenario 2: una API Fintech que falla su auditoría de seguridad
Considere un equipo de API de pagos que realiza pruebas de carga en su endpoint de autorización desde un pequeño conjunto de runners de prueba en la nube. El endpoint sostiene el RPS objetivo con latencia predecible. Semanas después, una auditoría de seguridad externa golpea el mismo endpoint desde un patrón de fuente distribuida y activa una regla de “fan-out anómalo” en el WAF. El rendimiento colapsa y los registros de auditoría muestran pausas de bloqueo que la prueba de carga nunca mostró.
El equipo había estado probando la aplicación a través del WAF, pero nunca con una forma de tráfico que el WAF considerara sospechosa. La auditoría fue la primera vez que el WAF realmente se activó. Pasar a una prueba de carga multi-IP, multi-ASN reproduce la desaceleración en preproducción, donde la regla se puede ajustar antes del lanzamiento. Este también es el modo de falla detrás de gran parte de la orientación sobre por qué las pruebas de carga HTTP tradicionales no son suficientes para las pilas modernas.
Escenario 3: una aplicación SaaS con una mala configuración silenciosa de Anycast
Considere una empresa SaaS B2B que mueve una API pública detrás de un balanceador de carga anycast y ejecuta la lista de verificación de preparación para pruebas de carga estándar. Las pruebas desde una región pasan sin problemas. Después del lanzamiento, los clientes en una región distante reportan una latencia media un orden de magnitud mayor de lo esperado. Resulta que el anuncio de anycast está mal configurado, y el tráfico de esa región se dirige a un POP lejano en lugar del más cercano. Ninguna prueba en una sola región podría haberlo detectado porque la mala configuración solo importaba cuando el resolvedor estaba fuera de la región fuente de prueba.
Este es el caso canónico para pruebas geodistribuidas. La corrección de la capa de enrutamiento no es visible desde una sola fuente.
Cómo LoadView Maneja las Pruebas de Carga Multi-IP
LoadView está construido alrededor de este problema. La red de inyección de carga geodistribuida de la plataforma abarca docenas de ubicaciones en Norteamérica, EMEA, APAC y Sudamérica. Cada ubicación es una región en la nube separada con su propio espacio IP de salida, por lo que cuando una prueba se ejecuta a través de todas ellas, la distribución de la fuente aque la aplicación objetivo refleje la forma geográfica y de red de los usuarios reales en lugar de un grupo de direcciones de salida en la nube.
Dos elecciones de diseño importan para los modos de fallo anteriores. Primero, LoadView ejecuta pruebas de carga de aplicaciones web en navegadores reales, por lo que los recuentos de conexiones, el comportamiento de coalescencia de HTTP/2 y la contabilidad por conexión en el servidor se parecen a usuarios reales en lugar de un cliente de protocolo simplificado. Segundo, los inyectores de carga se gestionan desde la nube, lo que significa que no hay un arnés que el equipo tenga que aprovisionar, no hay un grupo de puertos NAT-gateway que vigilar, y no hay tentación de ejecutar todos los generadores en una región porque eso es lo que el presupuesto permitió.
La combinación importa más que cada pieza por separado. Los navegadores reales desde una sola IP aún activarían los límites de tasa y las distorsiones del WAF descritas arriba. Muchas IPs ejecutando clientes solo de protocolo aún representarían incorrectamente el comportamiento del grupo de conexiones y HTTP/2. Los navegadores reales que impulsan pruebas de carga desde múltiples direcciones IP en muchas regiones reproducen tanto la forma de la red como la forma del cliente que la producción ve.
Una salvedad para establecer las expectativas correctamente: la red geo-distribuida de LoadView está construida sobre regiones de nube, lo que te da una amplia dispersión geográfica y de ASN, pero no salida residencial o de operador móvil por defecto. Para cargas de trabajo donde una porción significativa del tráfico de producción proviene de esas redes (aplicaciones de consumo con mucho tráfico móvil, por ejemplo), el patrón correcto es combinar los inyectores regionales en la nube de LoadView con una fuente residencial o de calidad de operador que controles por separado. La sección anterior sobre distribución realista de IP trata la diversidad de red como una propiedad del plan de prueba, no de ninguna herramienta individual.
Lista de verificación de implementación
Antes de la próxima prueba importante, sigue lo siguiente. El primer paso conecta esta lista de verificación con la discusión de distribución de fuente anterior: la forma de producción que mapeas ahí es el objetivo contra el que se dimensiona cada paso posterior.
Mapea la distribución de fuente en producción. Extrae una semana de registros de acceso y agrupa las solicitudes por región, ASN y densidad de prefijos IP. Una línea como awk '{print $1}' access.log | sort -u | wc -l te da un conteo de IPs únicas desde un registro combinado de NGINX o Apache; pásalo por una búsqueda GeoIP/ASN para obtener los cortes regionales y de ASN. La forma de esa distribución es el objetivo que tu prueba debería replicar. Si ya tienes datos de pruebas de usuarios concurrentes, úsalos como base.
Identifica los límites por IP en tu stack. Rate limiters en el borde, la puerta de enlace API, la aplicación y cualquier API de terceros. Tenga en cuenta el presupuesto en cada uno. Cualquier prueba que no supere el presupuesto más bajo en al menos una IP no está validando ese límite.
Elija regiones de inyección que coincidan con el peso de producción. Si el 60 por ciento del tráfico proviene de América del Norte, el 60 por ciento de los generadores deben estar allí. No rote en exceso para “probar todas las regiones por igual” si la producción está desequilibrada.
Confirme la diversidad de ASN de egreso. Si todos los generadores están en una nube, la prueba aún tiene el problema del egreso de la nube. Como mínimo, mezcle regiones; mejor aún, mezcle proveedores (por ejemplo, combine dos proveedores de nube con una red de salida residencial o de operador móvil).
Divida el informe por fuente. La latencia, la tasa de error y el rendimiento deben desglosarse por región y ASN. Si la división se reduce a un solo grupo, la prueba fue efectivamente de fuente única.
Reproduzca una regla WAF conocida que se active. Ejecute una pequeña prueba diseñada para activar una regla WAF que entienda y confirme que se active. Si no lo hace, el tráfico de prueba no se parece a la producción para su WAF, y el resto de los resultados son dudosos.
Preguntas Frecuentes
¿Por qué las pruebas de carga desde una sola IP producen números incorrectos?
El tráfico de producción llega desde muchas IPs a través de muchas redes. Limitadores de tasa, WAFs, bordes CDN, enrutadores anycast y grupos de conexión se comportan de manera diferente cuando el tráfico comparte una sola fuente. Una prueba con una sola IP estresa rutas que los usuarios reales nunca usan y omite rutas que los usuarios reales siempre usan, por lo que los números de latencia y rendimiento reflejan la configuración de la prueba en lugar del sistema.
¿Es la suplantación de IP en JMeter lo mismo que la prueba de carga con múltiples IPs?
No realmente. La suplantación de IP en JMeter rota la IP de origen a nivel del sistema operativo, pero los paquetes todavía salen de una máquina con una ruta predeterminada, un ASN y una ubicación geográfica. Los CDN, enrutadores anycast y muchos WAFs se basan en la ruta de red y el ASN, no solo en la dirección de origen de capa 3. La verdadera prueba de carga con múltiples IPs distribuye generadores a través de redes y regiones separadas.
¿Cuántas IPs necesito para una prueba de carga realista?
No hay un número único. El objetivo correcto es suficiente diversidad de IP y geográfica para que ninguna IP de origen única supere el límite de tasa por IP que desea validar, y que la distribución del borde CDN y enrutamiento coincida aproximadamente con la mezcla de tráfico de producción. Para la mayoría de las aplicaciones dirigidas al consumidor, eso significa docenas a cientos de IPs de origen distintas en varias regiones.
¿Cuándo es aceptable la prueba de carga con una sola IP?
La prueba con una sola IP está bien para comprobaciones a nivel de componente: un servicio backend detrás de un balanceador de carga interno sin límites por IP, un benchmark de controlador de base de datos o una prueba rápida donde solo importa que la respuesta sea correcta. En casi todos los casos, no es suficiente para la validación de rendimiento de extremo a extremo de un endpoint expuesto a internet.
¿Significa NAT que una sola IP¿puede representar a muchos usuarios?
NAT y CGNAT comprimen a muchos usuarios reales detrás de una dirección, por lo que los límites de velocidad por IP en producción ya consideran cierta agrupación. El problema con las pruebas de una sola IP no es que una IP no pueda representar a muchos usuarios, sino que una IP no puede representar la distribución de usuarios que realmente tienes. El tráfico real abarca miles de salidas NAT, no una.
Planifica una prueba de carga que devuelva números que puedas defender
Si el tráfico de prueba no coincide con la forma de origen de la producción, los resultados de la prueba no describen la producción. Las pruebas de carga distribuidas por IP en varias regiones no son un lujo para la planificación de capacidad, la validación de seguridad o la corrección del enrutamiento en el borde. Las pruebas de carga distribuidas ayudan a asegurar que tus pruebas reflejen cómo los usuarios reales acceden a tu aplicación. Comienza con la lista de verificación anterior, divide cada informe por fuente y valida tus suposiciones sobre el comportamiento del WAF y los límites de velocidad antes del próximo lanzamiento y no durante este.