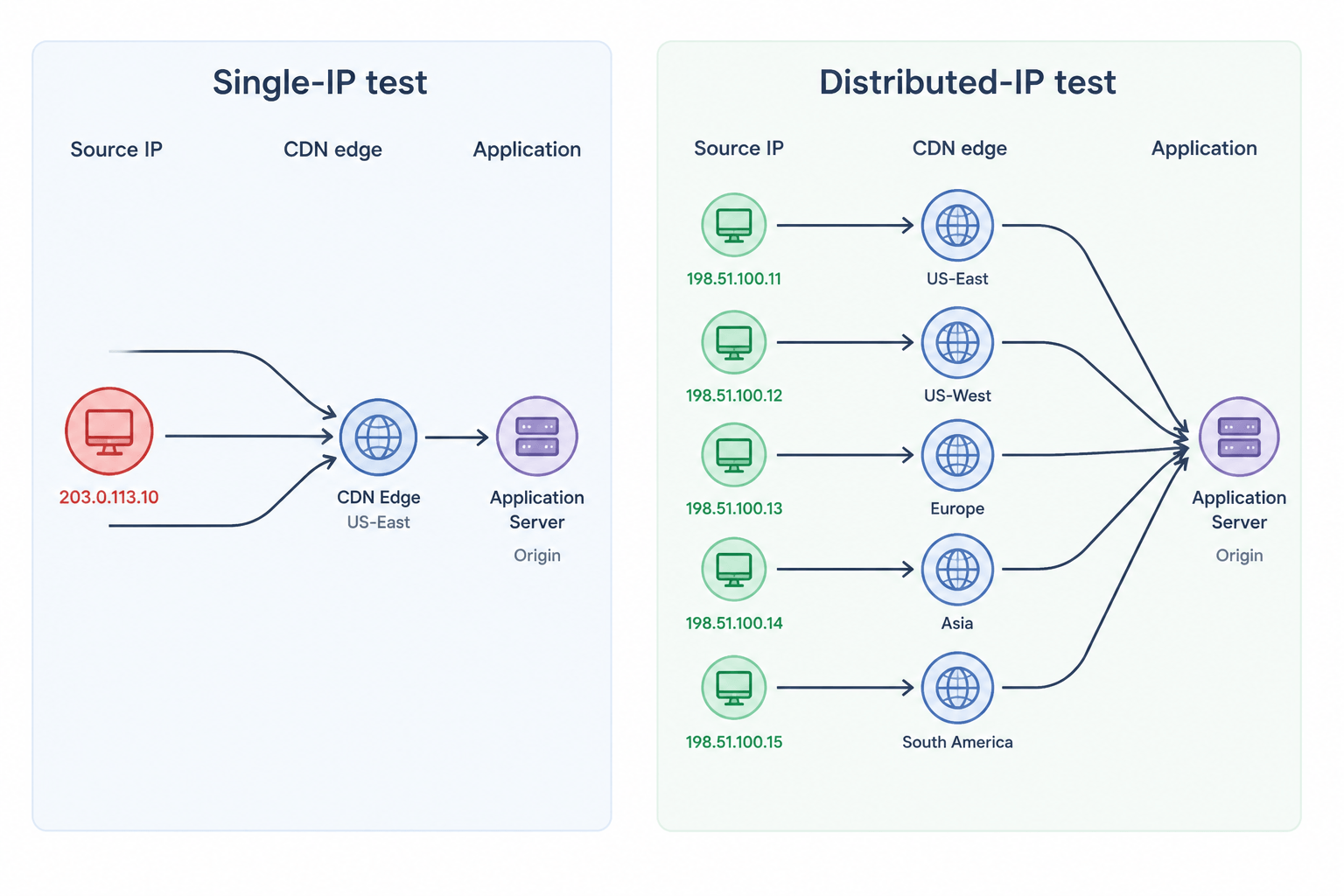
- Pourquoi un test à IP unique semble correct mais ne l’est pas
- Sept modes d’échec spécifiques
- Le piège de la sortie cloud
- À quoi ressemble une distribution réaliste des IPs
- IP unique vs IP distribuée : quand chaque solution est pertinente
- Scénarios du monde réel
- Comment LoadView gère les tests de charge multi-IP
- Liste de vérification pour la mise en œuvre
- FAQ
Pourquoi un test à IP unique semble correct mais ne l’est pas
Un test de charge à IP unique peut paraître réussi sur le papier. Le script s’exécute, les tableaux de bord se remplissent, et la latence reste dans la plage cible. Le problème est que les résultats reflètent souvent davantage la configuration du test que le trafic réel de production.
Le trafic de production n’arrive pas d’une seule adresse. Un point de terminaison destiné aux consommateurs voit du trafic provenant de milliers de fournisseurs d’accès résidentiels, d’opérateurs mobiles, de NATs d’entreprise et de proxys de centres de données. Chaque requête atterrit sur un nœud de périphérie CDN différent, traverse un middlebox différent, et atteint un shard différent du pool de connexions. Lorsque vous réduisez toute cette diversité à une seule IP source, chaque couche qui se base sur l’adresse sourcela robe commence à se comporter de manière qui n’a pas d’équivalent dans le monde réel.
Le résultat est des données de performance trompeuses qui ne reflètent pas le comportement réel en production.
Sept modes spécifiques d’échec des tests de charge à IP unique
Les tests de charge à IP unique peuvent déformer ou manquer complètement plusieurs comportements du monde réel.
1. Les limiteurs de débit retournent un mauvais chiffre
Les limiteurs de débit modernes fonctionnent par identifiant source, et l’identifiant le plus courant est l’IP source. Les algorithmes de type token-bucket, fenêtre fixe et fenêtre glissante partagent tous cette propriété. Même les équipes qui définissent des limites en fonction des jetons d’authentification ou des ID utilisateur appliquent presque toujours des limites par IP en dessous ; la couche IP est ce qui protège l’application contre les abus non authentifiés. Lorsqu’une charge lourde d’utilisateurs virtuels génère tout son trafic à partir d’une seule IP, le limiteur voit cette charge comme un seul client et commence à rejeter des requêtes bien avant que l’application ne ressente la pression. L’application semble rapide parce que le limiteur a absorbé la charge. En production, le même taux total de requêtes arriverait de milliers d’IP sources distinctes et le limiteur le laisserait passer.
Le miroir est également vrai. Si le limiteur dispose d’un budget généreux par IP, un test à IP unique ne se rapproche jamais de la limite agrégée au répartiteur de charge. L’application est bombardée et le limiteur n’intervient jamais, cachant le fait que le trafic en production serait partiellement abandonné.
2. Les WAF et la détection de bots se déclenchent sur la plateforme de test
Un WAF qui surveille des schémas de requêtes uniformes et en rafales provenant d’une IP réalise exactement le travail pour lequel il a été conçu. Il voit le test de charge, identifie le trafic et applique soit une limitation de débit, un défi, ou un blocage. Certaines équipes ne découvrent cela que lorsque le test atteint un plateau à un débit suspectement rond qui s’avère être le seuil du WAF. Les tests qui activent les mesures de protection contre les DDoS nécessitent des sources diversifiées pour la même raison — ces défenses sont typiquement séparées du WAF et encore plus dépendantes de la diversité des IP sources pour s’engager de manière réaliste.
Désactiver le WAF pour le test “corrige” le symptôme et crée un problème pire : le chemin du test ne correspond plus au chemin de production. Le trafic provenant de nombreuses IP est la seule façon de valider que l’application fonctionne pendant que le WAF est activé aux seuils de production.
3. La sélection de l’edge CDN se réduit à un seul nœud
Les CDN dirigent les requêtes vers l’edge le plus proche du client. À partir d’une IP unique, le trafic arrive sur un seul point POP d’edge. Le cache se remplit là, toutes les requêtes suivantes touchent un stockage chaud, et le test rapporte une latence de cache-hit pour toute la durée. Pendant ce temps, la longue traîne des edges froids dans d’autres régions n’est jamais sollicitée. Toute personne lisant les conseils sur les tests de charge des sites utilisant des CDN sees ceci est mentionné : le comportement du cache dépend de la distribution source, pas seulement du taux de requêtes.
Le cas inverse est également important. Le comportement de protection d’origine lors d’un cache-manqué, où un CDN rassemble les manques concurrents en une seule récupération à l’origine, est invisible depuis une seule IP. Vous ne pouvez pas valider la protection de l’origine sans un trafic que le CDN considère comme indépendant.
4. Les décisions de routage Anycast et GeoDNS ne se déclenchent jamais
Les IP Anycast acheminent les paquets vers le centre de données topologiquement le plus proche. GeoDNS résout un nom d’hôte en différentes IP en fonction de la localisation du résolveur. Ces deux décisions ont lieu avant que la requête n’atteigne votre application. Depuis une source de test unique, vous ne voyez jamais que le centre de données sur lequel votre lanceur de test se trouve. Le routage inter-régions, les chemins de secours et la latence vers des régions éloignées restent tous non testés.
Cela peut être un angle mort coûteux. Le test dans une seule région passe, l’application est déployée globalement et les utilisateurs dans des régions jamais touchées par le test subissent une latence que les tableaux de bord n’ont jamais montrée. Les tests de charge géodistribués existent précisément pour combler cette lacune.
5. La réutilisation du pool de connexions et la coalescence HTTP/2 faussent le débit
Les clients HTTP/2 et HTTP/3 ouvrent une connexion par origine et multiplexent les requêtes dessus. Depuis une seule IP avec un seul client, l’application voit une connexion longue durée transportant des milliers de flux. La comptabilisation par connexion du serveur, les fenêtres de contrôle de flux et le blocage en tête de ligne reflètent tous cette connexion unique. En production, vous avez des milliers de connexions, chacune avec sa propre fenêtre de contrôle de flux, contribuant indépendamment à la pression sur le planificateur.
Le même effet se produit au niveau du load balancer. Les métriques par connexion, la libération par timeout d’inactivité, et le comportement de vidange en redémarrage gracieux fonctionnent tous différemment avec une grosse connexion unique versus des milliers de petites. Vous ne voyez la distribution du comptage de connexions en production que lorsque vous générez la charge depuis de nombreux clients distincts répartis sur de nombreuses IP ; un test qui ne produit pas cette distribution ne peut valider aucun de ces aspects.
6. Épuisement des ports éphémères et du NAT Source sur le générateur
La plage de ports éphémères Linux donne à une seule IP source seulement des dizaines de milliers de ports par tuple de destination. Un générateur de charge poussant des taux élevés de connexions depuis une IP épuise les ports en quelques secondes, et le test plafonne sur le système de test au lieu du système testé. Les environnements cloud aggravent cela : une instance EC2 derrière une passerelle NAT partage un pool encore plus petit avec tout ce qui ressort par cette même passerelle. Les utilisateurs ayant rencontré cela le connaissent sous le nom de « le test ne montera pas plus haut », et cela est documenté dans de longs articles sur l’épuisement des ports TCP dans les tests à IP unique.
La solution n’est pas seulement des générateurs plus puissants. Il s’agit davantage de générateurs de charge avec leurs propres IP de sortie, de sorte que le pool de ports est répliqué plutôt que partagé.
7. L’observabilité se regroupe en un seul compartiment
De nombreux tableaux de bord de production regroupent le trafic par IP source, ASN ou région géographique. Un test à IP unique crée un seul compartiment, et chaque alerte, percentile et métrique de saturation se regroupe dans ce seul compartiment. Les ingénieurs qui examinent le test ne peuvent pas dire si la latence qu’ils voient est uniforme dans toutes les régions ou concentrée dans une seule. Ils ne peuvent pas non plus reproduire le découpage qu’ils utilisent lors d’un incident réel, où le premier réflexe est “montre-moi le p99 par région” ou “montre-moi le taux d’erreur par ASN”. Traiter les métriques de test de charge de la même manière que les métriques de production nécessite une diversité des sources dans l’entrée.
Le piège de la sortie cloud
La plupart des équipes qui essaient de répartir le test de charge sur plusieurs machines exécutent ces machines dans un seul compte cloud, dans une seule région, derrière une seule passerelle NAT. Le résultat est techniquement multi-IP mais pratiquement à source unique. Chaque paquet sort avec une IP source provenant du même ASN connu du fournisseur cloud. Les WAF, les fournisseurs de détection de bots et les fournisseurs de périphérie maintiennent tous des données de réputation sur les plages de sortie cloud ; beaucoup traitent le trafic provenant de ces plages avec une vigilance accrue par défaut.
Cela a deux conséquences. Premièrement, l’application considère le test comme un trafic de centre de données, qui est routé différemment du trafic résidentiel à chaque CDN et dans de nombreuses mises en œuvre anycast. Deuxièmement, vos tests s’exécutent depuis le même voisinage réseau que des charges concurrentes, ce qui rend la latence de base bruyante et la reproductibilité plus difficile. Les configurations génériques de tests de charge AWS peuvent gérer l’échelle mais pas la diversité des sources.
Le réalisme exige que le réseau d’injection de charge couvre plus d’un cloud, plusieurs régions, et idéalement un mélange d’egress de qualité centre de données et résidentielle (par exemple, combinant deux fournisseurs cloud avec un réseau de sortie résidentiel ou opérateur mobile) afin que le mélange IP/géo que votre application voit pendant le test ressemble à celui qu’elle voit en production.
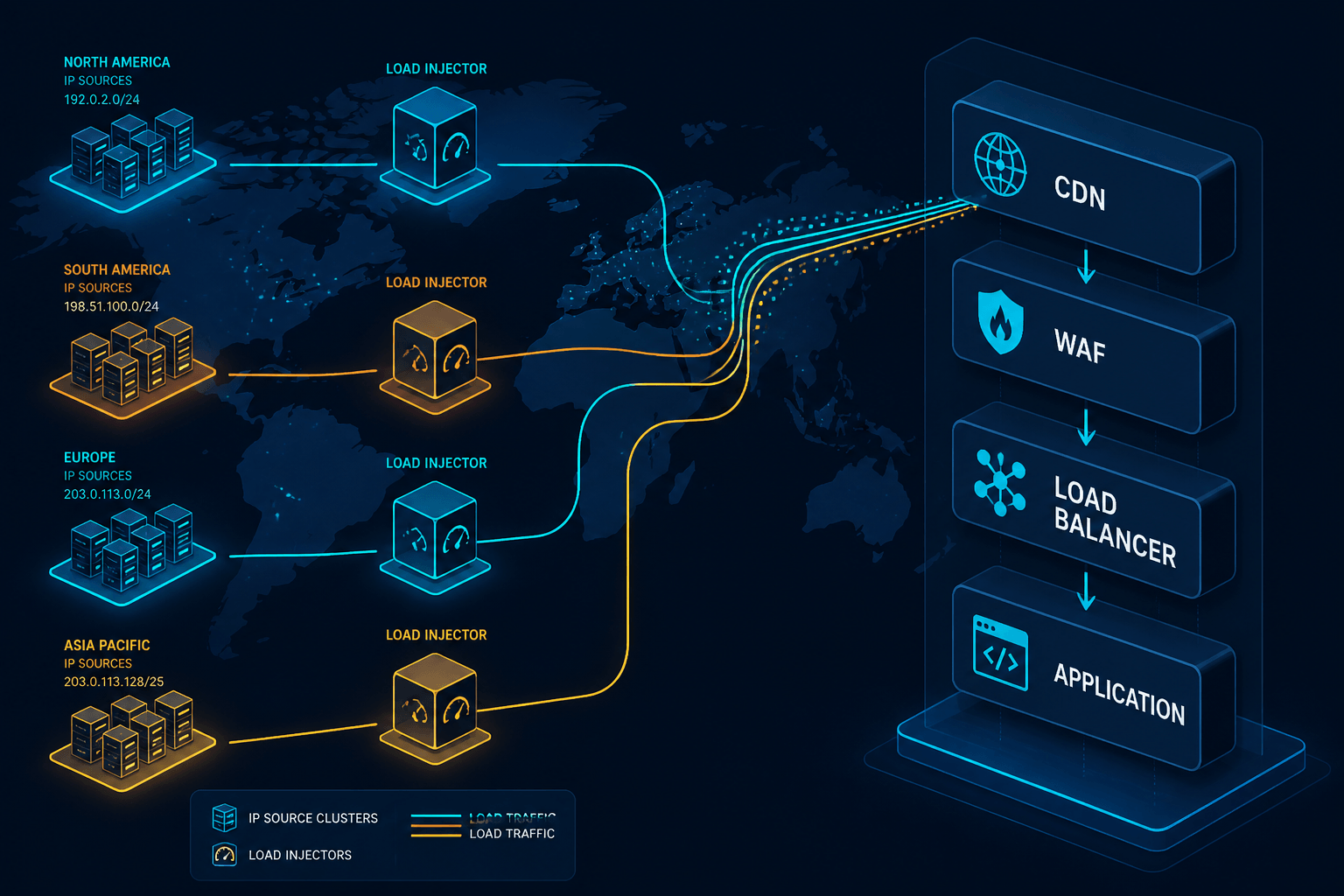
À quoi ressemble réellement une distribution IP réaliste
“Beaucoup d’IP” n’est pas un objectif. L’objectif est une distribution qui correspond à la production. Trois propriétés comptent.
Répartition géographique. Si 30 % des utilisateurs se trouvent en EMEA, 30 % en APAC et 40 % dans les Amériques, le test doit injecter dans des proportions à peu près identiques. C’est ce qui permet un routage anycast réaliste et une sélection correcte du CDN en bordure. Cela fait aussi ressortir les queues lentes que le test dans une seule région cache.
Diversité du réseau. Mélanger des FAI résidentiels, des opérateurs mobiles et des réseaux de centres de données expose l’application à l’ensemble des comportements de MTU, de pertes de paquets et de middleboxes que la production rencontre. Un test qui se déroule entièrement sur les réseaux de centres de données ignore la manière dont les réseaux mobiles renégocient le TLS ou comment le NAT de qualité opérateur regroupe les connexions.
Volume par IP qui ressemble à un utilisateur réel. Une IP réaliste ne génère pas mille requêtes par seconde. Elle génère le taux de requêtes de quelques utilisateurs réels derrière un NAT, plus de temps en temps un groupe émis par un utilisateur avancé. La simulation d’utilisateur virtuel qui respecte le volume par IP maintient les interactions avec la limitation de débit et le WAF dans des limites réalistes.
IP unique vs IP distribuée : quand chacun est approprié
| Objectif du test | IP unique acceptable ? | Pourquoi |
|---|---|---|
| Micro-benchmark de composant d’un service backend | Oui | Pas de chemin internet, pas de limite de débit par IP, pas de CDN. Le composant est le système testé. |
| Test de fumée d’un déploiement | Oui | Vous vérifiez la correction, pas la performance. |
| Validation de capacité d’un point d’accès internet | Non (dans presque tous les cas) | La limitation de débit, le WAF, le CDN et l’anycast déforment tous le résultat. |
| Test de scalabilité pré-lancement | Non | Les effets de pool de connexions, d’épuisement de ports et de sélection de bordure cassent le modèle. |
| Validation des seuils de limitation de débit par IP | Non | Par définition, cela requiert de nombreuses adresses IP source pour tester le seuil. |
| Réglage du contrôle de santé du répartiteur de charge | Parfois | LB interne uniquement. LB public nécessite des sources diverses. |
| Validation du routage géographique et du basculement | Non | Les décisions ne se déclenchent que lorsque le résolveur et l’IP source varient. |
Scénarios réels
Scénario 1 : un passage en caisse ecommerce qui « passe » jusqu’au Black Friday
Considérons un schéma courant. Un détaillant d’habillement réalise un test de charge avec de nombreux utilisateurs virtuels à partir d’une seule région cloud. La latence p95 du passage en caisse revient confortablement dans le SLO. Le Black Friday, la p95 bondit dans la fourchette de plusieurs secondes et l’abandon de panier augmente.
Deux choses ont tendance à apparaître dans ce genre d’analyse post-incident. Le CDN a servi la majorité du trafic de test à partir d’un seul POPqui est resté chaud pendant toute la durée du test. En production, le trafic est réparti sur de nombreux POP, dont plusieurs ont démarré à froid lors du pic. Le deuxième problème est généralement la limite de débit par IP sur un service en aval. Le test a immédiatement atteint le plafond pour une IP et est resté en dessous pendant toute la durée, ce qui a masqué une trajectoire de croissance illimitée dans le cache sous-jacent. La couverture Concurrent HTTP versus concurrent browsers explique pourquoi la forme du harnais importe autant que le nombre d’utilisateurs.
Scénario 2 : une API Fintech qui échoue à son audit de sécurité
Considérez une équipe API de paiements qui réalise des tests de charge sur leur point de terminaison d’autorisation à partir d’un petit ensemble de runners de test cloud. Le point de terminaison soutient le RPS cible avec une latence prévisible. Des semaines plus tard, un audit externe de sécurité atteint le même point de terminaison à partir d’un modèle de source distribué et déclenche une règle “d’expansion anormale” sur le WAF. Le débit s’effondre et les journaux d’audit notent des pauses de blocage que le test de charge n’avait jamais détectées.
L’équipe avait testé l’application via le WAF, mais jamais avec une forme de trafic que le WAF considérait comme suspecte. L’audit est la première fois que le WAF s’engage réellement. Passer à un test de charge multi-IP, multi-ASN reproduit le ralentissement en pré-production, où la règle peut être ajustée avant le lancement. C’est aussi le mode de défaillance derrière une grande partie des recommandations sur pourquoi les tests de charge HTTP traditionnels ne suffisent pas pour les stacks modernes.
Scénario 3 : une application SaaS avec une mauvaise configuration silencieuse de l’anycast
Considérez une entreprise SaaS B2B qui place une API publique derrière un répartiteur de charge anycast et exécute la checklist standard de préparation des tests de charge. Les tests d’une région passent sans problème. Après le lancement, des clients d’une région éloignée signalent une latence médiane dix fois plus élevée que prévu. L’annonce anycast s’avère mal configurée, et le trafic de cette région est acheminé vers un POP éloigné au lieu du plus proche. Aucun test d’une seule région n’aurait pu le détecter parce que la mauvaise configuration ne comptait que lorsque le résolveur était en dehors de la région source de test.
C’est le cas canonique pour les tests géo-distribués. La justesse de la couche de routage n’est pas visible depuis une seule source.
Comment LoadView gère les tests de charge multi-IP
LoadView est construit autour de ce problème. Le réseau d’injection de charge géo-distribué de la plateforme couvre des dizaines d’emplacements en Amérique du Nord, EMEA, APAC et Amérique du Sud. Chaque emplacement est une région cloud distincte avec son propre espace IP de sortie, donc lorsqu’un test s’exécute sur toutes ces régions, la distribution des sources at que l’application cible reflète la forme géographique et réseau des utilisateurs réels plutôt qu’un groupe d’adresses de sortie cloud.
Deux choix de conception sont importants pour les modes de défaillance ci-dessus. D’abord, LoadView exécute des tests de charge d’applications web dans de vrais navigateurs, de sorte que les comptes de connexion, le comportement de coalescence HTTP/2 et la comptabilisation par connexion sur le serveur ressemblent à des utilisateurs réels plutôt qu’à un client de protocole simplifié. Ensuite, les injecteurs de charge sont gérés côté cloud, ce qui signifie qu’il n’y a pas de harnais à provisionner par l’équipe, pas de pool de ports de passerelle NAT à surveiller, et pas de tentation de faire tourner tous les générateurs dans une seule région parce que le budget le permettait.
La combinaison importe plus que chaque élément pris séparément. De vrais navigateurs depuis une seule IP déclencheraient toujours les limites de débit et les distorsions WAF décrites ci-dessus. Plusieurs IP exécutant des clients protocolaires seuls représenteraient toujours mal la gestion des pools de connexion et le comportement HTTP/2. De vrais navigateurs provoquant des tests de charge depuis plusieurs adresses IP à travers de nombreuses régions reproduisent à la fois la forme réseau et la forme client que la production voit.
Une mise en garde pour bien définir les attentes : le réseau géo-distribué de LoadView est construit sur des régions cloud, ce qui vous offre une large répartition géographique et ASN mais pas de sortie résidentielle ni via opérateur mobile prête à l’emploi. Pour des charges de travail où une part significative du trafic de production provient de ces réseaux (applications grand public fortement mobiles, par exemple), le bon schéma est de combiner les injecteurs cloud régionaux de LoadView avec une source résidentielle ou de niveau opérateur que vous gérez séparément. La section précédente sur la distribution IP réaliste considère la diversité réseau comme une propriété du plan de test, pas d’un outil unique.
Checklist de mise en œuvre
Avant le prochain test important, passez en revue les éléments suivants. La première étape relie cette checklist à la discussion sur la distribution des sources ci-dessus — la forme production que vous y cartographiez est la cible à laquelle toutes les étapes ultérieures sont calibrées.
Cartographiez la distribution des sources en production. Récupérez une semaine de logs d’accès et regroupez les requêtes par région, ASN et densité de préfixes IP. Une commande simple comme awk '{print $1}' access.log | sort -u | wc -l vous donne un compte d’IP uniques à partir d’un log combiné NGINX ou Apache ; passez les résultats dans une recherche GeoIP/ASN pour les découpes régionales et ASN. La forme de cette distribution est la cible que votre test doit reproduire. Si vous avez déjà des données de tests utilisateurs concurrents, utilisez-les comme référence.
Identifiez les limites par IP dans votre stack. Rate limiters à la périphérie, la passerelle API, l’application et toutes les API tierces. Notez le budget sur chacun. Tout test qui ne dépasse pas le budget le plus bas sur au moins une IP ne valide pas cette limite.
Choisissez les régions d’injection en fonction du poids de production. Si 60 % du trafic provient d’Amérique du Nord, 60 % des générateurs doivent s’y trouver. Ne forcez pas une rotation excessive pour « tester toutes les régions également » si la production est déséquilibrée.
Confirmez la diversité des ASN de sortie. Si chaque générateur est dans un seul cloud, le test a toujours le problème de sortie cloud. Au minimum, mélangez les régions ; mieux, mélangez les fournisseurs (par exemple, combinez deux fournisseurs cloud avec un réseau de sortie résidentiel ou opérateur mobile).
Divisez le rapport par source. La latence, le taux d’erreur et le débit doivent chacun être ventilés par région et ASN. Si la division se réduit à un seul ensemble, le test était effectivement à source unique.
Reproduisez un déclenchement connu d’une règle WAF. Lancez un petit test conçu pour déclencher une règle WAF que vous comprenez, et confirmez qu’elle se déclenche. Sinon, le trafic de test ne ressemble pas à la production pour votre WAF, et le reste des résultats est suspect.
FAQ
Pourquoi les tests de charge à partir d’une seule IP produisent-ils des chiffres erronés ?
Le trafic de production provient de nombreuses IP sur de nombreux réseaux. Les limiteurs de débit, les WAF, les bords CDN, les routeurs anycast et les pools de connexions se comportent tous différemment lorsque le trafic provient d’une seule source. Un test à IP unique sollicite des chemins que les utilisateurs réels ne touchent jamais et ignore les chemins que les utilisateurs réels touchent toujours, donc la latence et les chiffres de débit reflètent la configuration du test plutôt que le système.
Le spoofing IP dans JMeter est-il identique au test de charge multi-IP ?
Pas vraiment. Le spoofing IP dans JMeter fait tourner l’IP source au niveau du système d’exploitation, mais les paquets quittent toujours une seule machine avec une seule route par défaut, un seul ASN et une seule localisation géographique. Les CDN, les routeurs anycast et de nombreux WAF se basent sur le chemin réseau et l’ASN, pas seulement sur l’adresse source de couche 3. Un vrai test de charge multi-IP distribue les générateurs sur différents réseaux et régions.
Combien d’IPs sont nécessaires pour un test de charge réaliste ?
Il n’y a pas de chiffre unique. La cible correcte est une diversité suffisante d’IP et géographique telle qu’aucune IP source unique ne dépasse la limite de débit par IP que vous souhaitez valider, et que la distribution du bord CDN et du routage correspond approximativement à votre mix de trafic en production. Pour la plupart des applications grand public, cela signifie des dizaines à des centaines d’IP sources distinctes réparties sur plusieurs régions.
Quand un test de charge à IP unique est-il acceptable ?
Les tests à IP unique conviennent aux vérifications au niveau composant : un service backend derrière un équilibreur de charge interne sans limite par IP, un benchmark de pilote de base de données ou un test rapide où seule la correction de la réponse importe. Dans presque tous les cas, ce n’est pas suffisant pour une validation des performances de bout en bout d’un point d’accès internet.
Le NAT signifie-t-il qu’une seule IPpeuvent représenter de nombreux utilisateurs?
Le NAT et le CGNAT compressent en effet de nombreux utilisateurs réels derrière une seule adresse, donc les limites de taux par IP en production prennent déjà en compte une certaine agrégation. Le problème avec les tests sur une seule IP n’est pas qu’une IP ne peut pas représenter de nombreux utilisateurs, mais qu’une IP ne peut pas représenter la répartition des utilisateurs que vous avez réellement. Le trafic réel s’étend sur des milliers de sorties NAT, pas une seule.
Planifiez un test de charge qui retourne des chiffres que vous pouvez défendre
Si le trafic de test ne correspond pas à la forme source de la production, les résultats du test ne décrivent pas la production. Les tests de charge distribués sur plusieurs régions ne sont pas un luxe pour la planification de capacité, la validation de la sécurité, ou la correction du routage en périphérie. Les tests de charge distribués aident à garantir que vos tests reflètent la façon dont les vrais utilisateurs accèdent à votre application. Commencez par la liste de contrôle ci-dessus, analysez chaque rapport par source, et validez vos hypothèses sur le comportement du WAF et des limites de taux avant le prochain lancement plutôt que pendant celui-ci.