Lorsque les équipes parlent de tests de performance, l’attention se porte souvent directement sur le chiffre : combien d’utilisateurs le système peut-il supporter ? Mais ce chiffre, pris isolément, signifie très peu. Un système qui « survit » à 1 000 ou même 50 000 utilisateurs ne vous dit pas quand les performances ont commencé à se dégrader, comment les erreurs sont apparues, ni si l’application s’est remise après la baisse de la charge.
Ce qui compte tout autant (et souvent davantage), c’est la manière dont cette charge est appliquée. La forme du trafic que vous générez pendant un test, connue sous le nom de courbe de charge, détermine si vous repartirez avec un simple résultat binaire de réussite/échec ou avec de véritables informations techniques exploitables. Une courbe mal choisie ne vous dira que « oui, le site est resté opérationnel » ou « non, il a planté ». À l’inverse, une courbe bien structurée révèle des seuils, des goulets d’étranglement et la résilience : où les premières fissures apparaissent, à quelle vitesse elles se propagent et si le système reprend son fonctionnement une fois la pression retombée.
C’est pourquoi la courbe de charge est aussi importante que la taille du test. Une montée brutale jusqu’à un grand nombre peut paraître impressionnante sur un graphique, mais elle masque l’histoire derrière le résultat. Des courbes réfléchies exposent le vrai comportement de votre application sous contrainte, permettant d’identifier les faiblesses avant que vos utilisateurs ne les subissent.
Qu’est-ce qu’une courbe de charge ?
Une courbe de charge est la progression du trafic dans le temps. Plutôt que de se concentrer sur le nombre total d’utilisateurs virtuels, pensez-y comme une gradation ou une file d’attente qui représente comment les personnes arrivent et interagissent réellement avec votre système. Les ingénieurs de performance distinguent souvent la concurrence (utilisateurs simultanés) et le débit (transactions par seconde), car les deux influencent le comportement du système différemment.
- À quelle vitesse les utilisateurs augmentent-ils ? Un filet régulier ne ressemble pas à un déluge.
- Arrivent-ils de manière constante ou par rafales ? Différentes courbes révèlent différents risques.
- Faites-vous des pauses à certains paliers pour observer la stabilité ? Ces plateaux peuvent révéler des fissures subtiles.
- Maintenez-vous la charge au sommet, ou relâchez-vous le trafic aussi rapidement que vous l’avez appliqué ? La demande réelle implique souvent les deux.
C’est là la vraie valeur du façonnage de la courbe : il ne s’agit pas seulement d’atteindre la charge maximale, mais d’observer comment le système se comporte à chaque étape.
La seule notion de concurrence n’explique pas toute l’histoire. Deux tests annonçant « 1 000 utilisateurs concurrents » peuvent être radicalement différents. L’un peut être une montée douce qui ne vous dit que si le site tenait à la fin. L’autre peut être une succession de paliers qui révèle précisément où la latence a augmenté, où les taux d’erreur ont commencé et à quel niveau votre infrastructure a fléchi.
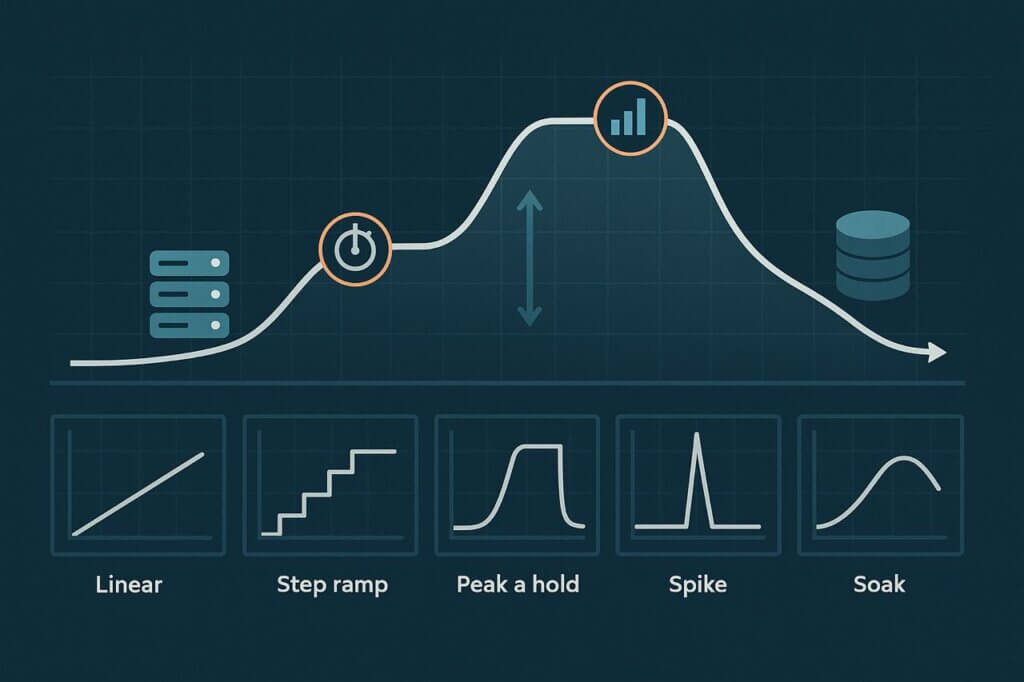
Courbes de charge courantes en tests de performance
Différentes courbes de charge existent pour une raison : chacune met au jour un type de faiblesse différent. Parcourons les modèles les plus couramment utilisés.
Montée linéaire
Le test le plus simple. Les utilisateurs virtuels sont ajoutés de manière régulière jusqu’à atteindre la cible. Cette courbe est facile à configurer et utile pour les phases de warm-up, mais elle est aussi la moins informative. Tout ce que vous apprenez, c’est si le système a résisté à la charge complète. Vous ne voyez pas quand les choses ont commencé à mal tourner, seulement si elles étaient mauvaises à la fin.
Montée par paliers (escalier)
Une approche plus réfléchie. Le trafic monte par incréments, avec des pauses à chaque palier. Ces plateaux sont des fenêtres d’observation : des moments où la latence, les erreurs et l’utilisation des ressources se stabilisent afin que vous puissiez déterminer précisément quand les performances commencent à se dégrader. Les fissures sont-elles apparues à 10 utilisateurs ? 60 ? 90 ? L’escalier met en évidence des seuils qu’une montée linéaire pourrait manquer.
Montée et maintien
Ici, le trafic monte jusqu’à une cible puis s’y maintient. Il s’agit moins de trouver le point de rupture que de voir si votre système peut soutenir la pression une fois dans un état stable. Cette courbe est précieuse pour vérifier le comportement de la mise à l’échelle automatique, le réglage des pools de connexions ou si les services en aval peuvent supporter une charge constante.
Test de pic
Toutes les défaillances ne sont pas progressives. Parfois, le trafic arrive d’un coup. Un test de pic simule ces afflux — lancement de produit, Black Friday ou un épisode viral sur les réseaux sociaux. Vous découvrez à quel point votre plateforme absorbe un impact soudain et si elle récupère correctement une fois la ruée passée.
Test d’endurance (soak)
Les tests courts manquent les problèmes qui n’apparaissent qu’après des heures de charge. Un test d’endurance s’exécute à une intensité modérée pendant de longues durées. C’est ainsi que l’on détecte les fuites de mémoire, l’épuisement des ressources, la latence qui augmente progressivement et l’instabilité qui se construit au fil du temps. Pour les plateformes critiques — financières, SaaS ou gouvernementales — les tests d’endurance révèlent souvent les défauts de fiabilité les plus sérieux.
Pourquoi la courbe la plus simple est souvent la pire
Il est tentant de commencer par une montée linéaire douce. C’est propre, facile à configurer, et cela donne un joli résultat arrondi : le nombre maximal d’utilisateurs que votre système a supporté avant d’échouer. Mais propre ne veut pas dire utile.
Le problème d’une montée linéaire abrupte est qu’elle masque des détails critiques. Les performances ont-elles commencé à faiblir à 200 utilisateurs mais se sont effondrées à 800 ? La latence a-t-elle augmenté progressivement bien avant l’apparition des erreurs ? Beaucoup d’équipes ont appris à leurs dépens qu’en se fiant uniquement à cette courbe, elles restent aveugles aux signaux précurseurs.
Si vous exécutez une montée brute, vous ne le saurez pas. Vous n’aurez qu’une réponse binaire. Vous saurez seulement si le système a tenu ou non, et vous aurez peu d’indication sur les raisons. Ça peut suffire pour une démo rapide, mais c’est inutile pour des décisions d’ingénierie et dangereux en production.
Comment choisir la bonne courbe selon vos objectifs
Il n’existe pas une courbe qui convienne à toutes les situations. Le bon choix dépend du type de défauts que vous voulez mettre au jour et des enseignements que vous attendez du test. Associer judicieusement la courbe à l’objectif est ce qui distingue un test de performance utile d’un joli graphique sans valeur.
Pour la découverte de capacité, les montées par paliers sont les plus révélatrices. En maintenant chaque palier, vous pouvez observer les métriques se stabiliser et identifier le point exact où les temps de réponse commencent à fléchir ou où les taux d’erreur augmentent. Cette précision facilite la traçabilité des problèmes vers des composants spécifiques — base de données saturée, cache surchargé ou pools de threads épuisés.
Lorsqu’il s’agit de tester la résilience sous contrainte, les tests de pic et les montées et maintien sont inestimables. Un pic soudain montre si votre système peut gérer une poussée inattendue sans défaillances en cascade. Le maintien au pic révèle comment le système se comporte une fois qu’il atteint une charge élevée et stable : les auto-scalers réagissent-ils à temps, les performances se stabilisent-elles, ou la plateforme s’effondre-t-elle lentement ?
Pour la fiabilité à long terme, rien ne vaut un test d’endurance. Les problèmes comme les fuites de mémoire, l’accumulation de files d’attente et la dégradation progressive de la latence n’apparaissent pas lors de courtes exécutions. Maintenir un trafic modéré pendant des heures ou l’ensemble d’une journée de travail montre si votre système peut supporter l’usure lente de l’utilisation réelle.
Le principe est simple : choisissez la courbe qui correspond au risque que vous devez comprendre. Tout le reste produit des données impressionnantes mais peu utiles pour améliorer la fiabilité.
Conseils pratiques pour concevoir des courbes de charge
Choisir la courbe n’est que la moitié du travail — l’autre moitié consiste à la modeler correctement. Des tests mal conçus peuvent faire perdre des heures et masquer des seuils, tandis que des tests bien conçus agissent comme des expériences contrôlées qui expliquent non seulement si le système échoue, mais comment et pourquoi.
- La vitesse de montée compte. Trop agressive et vous dépasserez le seuil de défaillance sans le détecter. Trop lente et vous n’atteindrez jamais une charge significative dans la fenêtre prévue. Les meilleures conceptions équilibrent réalisme et visibilité.
- Laissez les paliers se stabiliser. Quand vous marquez une pause à chaque niveau, donnez au système le temps de chauffer les caches, de déclencher la mise à l’échelle automatique et de laisser les processus en arrière-plan se stabiliser. Sinon, vous mesurez le chaos, pas l’état stable.
- Regardez au-delà des plantages totaux. Les pannes sont spectaculaires, mais les métriques subtiles en disent souvent plus : augmentation des p95/p99, pourcentages d’erreur croissants, ou CPU/mémoire qui approchent de la saturation. Ce sont des signaux d’alerte précoces qui permettent de corriger les goulets d’étranglement avant que les utilisateurs ne les remarquent.
- Restez sobre. Plus de courbes ne sont pas toujours mieux. En pratique, deux ou trois modèles soigneusement choisis, comme une montée par paliers pour identifier les seuils et un test d’endurance pour la résistance, fournissent la plupart des informations exploitables sans complexifier inutilement votre suite de tests.
Considérez vos courbes comme des expériences : conçues avec intention, exécutées avec rigueur et observées pour en extraire des signaux qui expliquent non seulement si le système échoue, mais comment et pourquoi.
Scénarios d’exemple
E-commerce : trafic du Black Friday
Les plateformes de vente vivent et meurent selon leurs performances lors d’événements comme le Black Friday. Le trafic ne s’accumule pas lentement — il afflue dès l’ouverture des ventes. Un test de pic montre si le site peut survivre à la vague, tandis qu’un test de montée et maintien valide si les flux de paiement restent stables sous une forte demande pendant des heures.
Plateformes SaaS : pics d’onboarding
Lorsqu’un nouveau produit est lancé ou qu’un gros client est onboardé, les services partagés comme l’authentification ou les bases de données peuvent être saturés. Une montée par paliers met en évidence le seuil de concurrence où ces services commencent à se dégrader, fournissant aux ingénieurs des éléments concrets pour renforcer les points faibles avant que les clients ne subissent des problèmes.
Systèmes financiers : heures de trading
Les plateformes de trading et les applications financières doivent rester stables pendant de longues sessions. Un test d’endurance couvrant les heures de marché révèle des défaillances lentes comme les fuites de mémoire, l’accumulation de files d’attente et la dégradation de la latence que les tests courts ne détectent pas. Ces problèmes peuvent ne pas provoquer d’arrêt brutal, mais ils érodent silencieusement la fiabilité.
Médias et divertissement : événements de streaming en direct
Les plateformes de streaming connaissent souvent une montée régulière suivie d’une brusque augmentation au début de l’événement. Une courbe hybride, telle qu’une montée par paliers suivie d’un pic, montre si l’infrastructure vidéo peut gérer à la fois le warm-up et l’afflux soudain de spectateurs sans dégrader la qualité du flux.
Services gouvernementaux et publics : pics liés aux échéances
Les portails fiscaux, les systèmes de permis et les demandes d’aides connaissent souvent des pics liés aux dates limites. Une montée par paliers combinée à un maintien au pic révèle si ces systèmes peuvent gérer des jours d’augmentation progressive du trafic et rester utilisables lorsque la charge atteint son maximum juste avant la clôture.
Conclusion
La forme de votre test est aussi importante que sa taille. Une courbe mal conçue peut vous offrir un titre accrocheur du type « nous avons supporté 10 000 utilisateurs », mais elle ne vous montrera pas où le système a réellement commencé à craquer ni comment les utilisateurs ont été impactés.
De bonnes courbes de charge apportent plus que des droits de vantardise. Elles révèlent des seuils, pinpointent les goulets d’étranglement et montrent si le système peut se rétablir correctement une fois la pression retombée. C’est pourquoi les ingénieurs de performance considèrent la conception des courbes comme la préparation d’une expérience, pas comme un ornement.
Ne traitez donc pas la courbe comme une réflexion après coup. Traitez-la comme l’instrument de votre test. Choisissez vos courbes délibérément, adaptez-les à vos questions, et vous obtiendrez des résultats qui améliorent réellement les performances plutôt que de simples trophées de rapport.